📝 Paper Summary
LLM Reasoning
Test-Time Compute
Reinforcement Learning
MRT treats test-time reasoning as a meta-RL problem, training LLMs to minimize cumulative regret by balancing exploration and exploitation across reasoning episodes without needing outcome labels for every step.
Core Problem
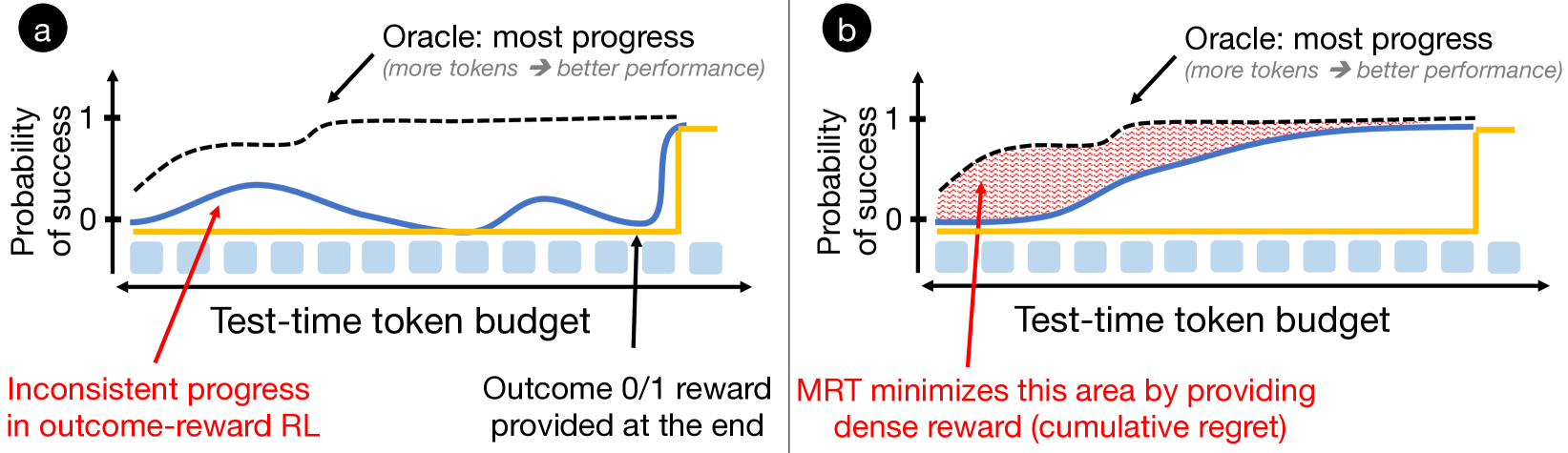
Current methods for scaling test-time compute (like outcome-reward RL) often fail to use additional tokens efficiently or discover solutions to harder problems when the budget increases.
Why it matters:
- Standard outcome-reward RL does not differentiate between solutions that make steady progress and those that don't, leading to inefficient token usage.
- Models trained with fixed budgets often fail to generalize to larger test-time budgets, either terminating prematurely or looping without progress.
- Existing long-CoT models tend to use too many tokens on easy questions while failing to solve harder ones even with more compute.
Concrete Example:
A standard RL-trained model might generate a long chain of thought that essentially repeats the same wrong logic multiple times to fill the budget. In contrast, an optimal policy should try a strategy, recognize failure, backtrack (exploration), and then commit to a promising path (exploitation).
Key Novelty
Meta Reinforcement Fine-Tuning (MRT)
- Formalizes the reasoning process as a meta-RL problem where the LLM is an agent trying to minimize 'cumulative regret' over a sequence of reasoning episodes.
- Introduces a dense 'progress reward' bonus that quantifies the change in likelihood of eventual success between episodes, encouraging steady progress rather than just final correctness.
- Trains the model to be 'budget-agnostic,' effectively using small budgets for easy problems while scaling effectively to larger budgets for hard problems.
Architecture
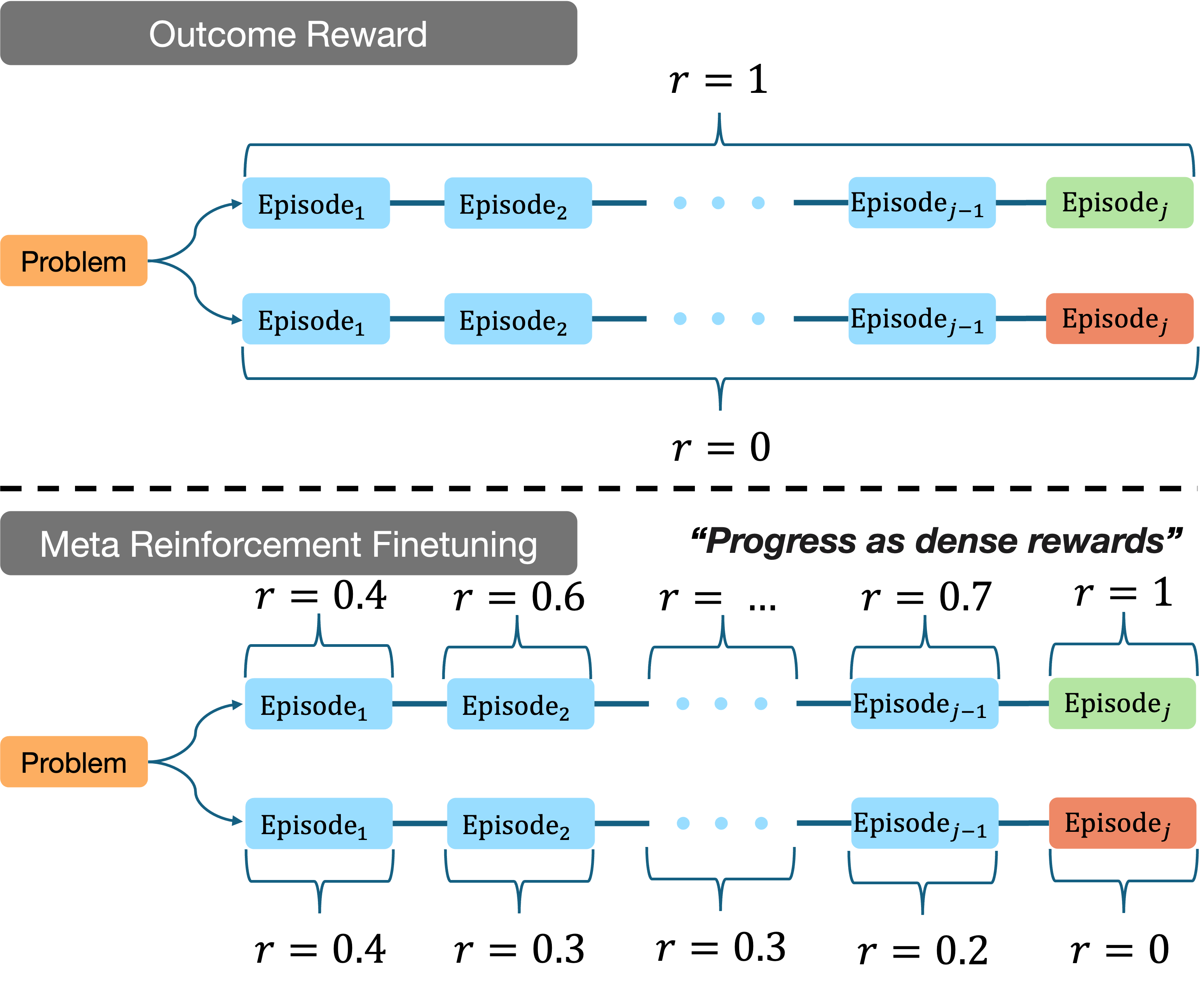
Illustration of the Meta Reinforcement Fine-Tuning (MRT) framework.
Evaluation Highlights
- 2-3x relative gain in accuracy over base models on math benchmarks (AIME 2024, AIME 2025, AMC 2023) compared to standard outcome-reward RL (GRPO).
- 1.5x improvement in token efficiency compared to GRPO, meaning the model solves problems using fewer tokens on average.
- Maintains lower cumulative regret and steadier progress even when extrapolated to 2x larger token budgets than seen during training.
Breakthrough Assessment
8/10
Provides a theoretically grounded framework (meta-RL/regret minimization) for test-time compute, addressing the efficiency/scaling issues of current 'reasoning' models like DeepSeek-R1. Strong empirical efficiency gains.