📝 Paper Summary
Vision-Language Models
Reinforcement Learning
Reasoning
Visual-RFT enhances Large Vision-Language Models by applying reinforcement learning with task-specific verifiable rewards—like IoU for detection—to optimize reasoning and accuracy without relying solely on supervised data.
Core Problem
Supervised Fine-Tuning (SFT) relies on mimicking large amounts of ground-truth data, which limits data efficiency and generalization capabilities in visual tasks, often leading to rote memorization rather than true reasoning.
Why it matters:
- SFT is inefficient in data-scarce domains (e.g., few-shot learning), whereas Reinforcement Fine-Tuning (RFT) has shown great success in math/code by learning from feedback.
- Applying RFT to visual domains is under-explored because defining 'verifiable rewards' for visual perception is more complex than checking a math answer.
- Current LVLMs struggle to generalize to new concepts or fine-grained categories when training data is limited (e.g., ~100 samples).
Concrete Example:
In one-shot fine-grained image classification with only ~100 samples, a standard SFT model's accuracy drops by 4.3% because it fails to learn robust features from limited examples. In contrast, Visual-RFT improves accuracy by 24.3% by exploring reasoning paths and receiving binary rewards for correct classifications.
Key Novelty
Visual Reinforcement Fine-Tuning (Visual-RFT)
- Extends the 'reasoning-first' RL paradigm (inspired by DeepSeek-R1) to visual tasks by defining rule-based verifiable rewards (e.g., IoU checks, accuracy matches) instead of using learned reward models.
- Encourages the model to generate 'thought' tokens explaining its visual analysis before outputting the final answer, optimizing this process via Group Relative Policy Optimization (GRPO) to discover effective reasoning strategies.
Architecture
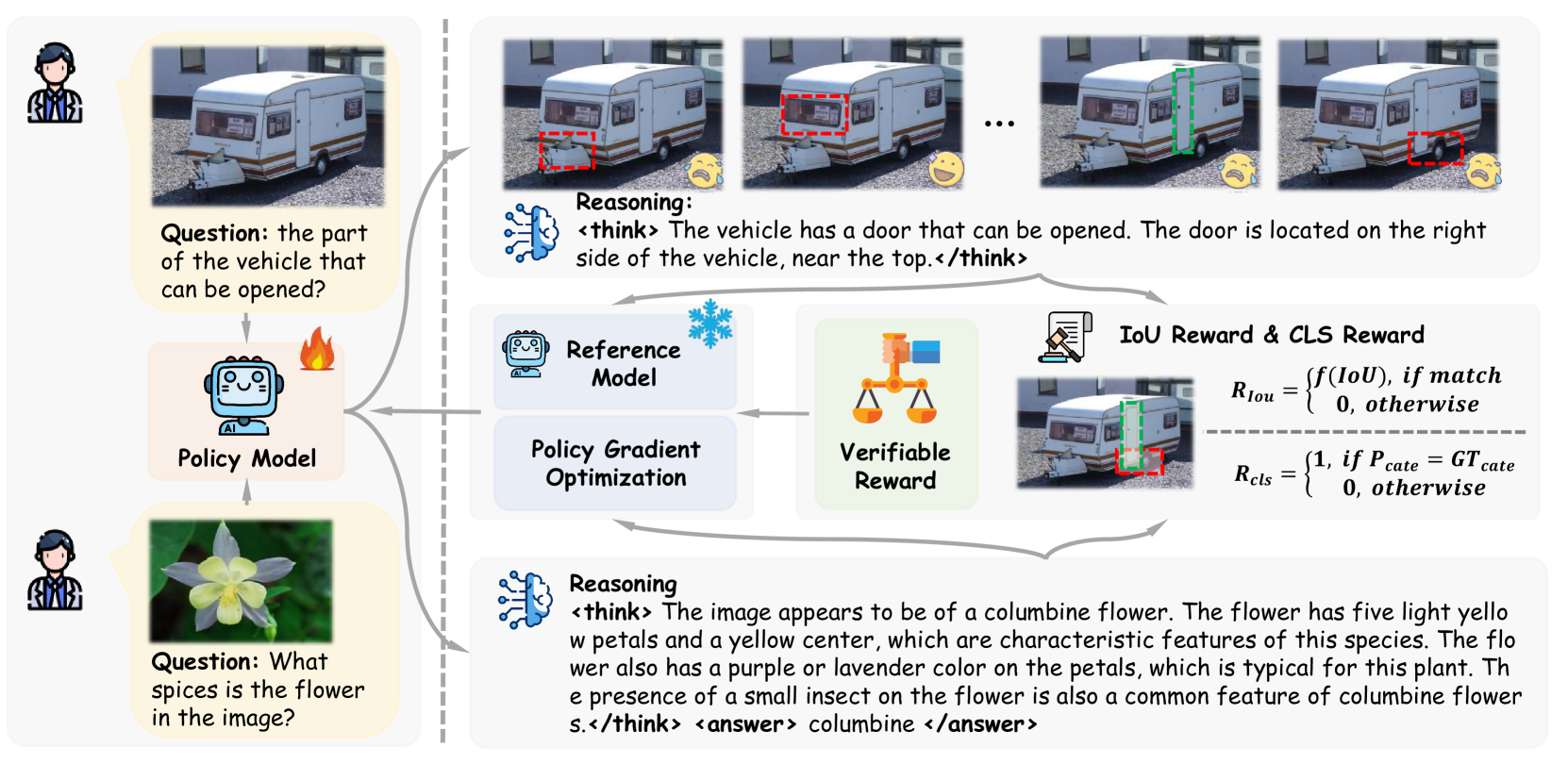
The Visual-RFT training framework compared to standard SFT. It illustrates the cycle of generating multiple reasoning trajectories, scoring them with verifiable visual rewards, and updating via GRPO.
Evaluation Highlights
- Improves mAP from 9.8 to 31.3 (+21.5) on new classes of COCO open-vocabulary object detection using a 2B parameter model.
- Achieves +24.3% accuracy improvement over the baseline in one-shot fine-grained image classification, while SFT degrades performance.
- Exceeds baselines by +21.9 mAP on COCO two-shot detection and +15.4 mAP on LVIS few-shot detection.
Breakthrough Assessment
8/10
Successfully translates the 'reasoning RL' paradigm (o1/R1) to vision-language tasks with impressive few-shot gains, establishing a new direction for data-efficient LVLM training using verifiable visual rewards.