📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Visual Instruction Tuning
LLaVA extends instruction tuning to the multimodal space by training a large language model on machine-generated vision-language instruction data created via GPT-4.
Core Problem
Community access to vision-language instruction-following data is scarce, limiting the ability to build general-purpose multimodal assistants that follow human intent.
Why it matters:
- Existing vision models usually have fixed interfaces (e.g., classification, detection) with limited interactivity and adaptability to user instructions
- Current open-source multimodal models are not explicitly tuned with instruction data, causing performance to fall short on multimodal tasks compared to language-only equivalents
- Creating multimodal instruction data via human crowd-sourcing is time-consuming and ill-defined
Concrete Example:
A standard image-text pair might be 'A man with luggage near a car.' A simple expansion to 'Describe the image' lacks depth. LLaVA's approach generates complex reasoning instructions like 'What challenges do these people face?' requiring the model to infer that 'fitting all luggage into the SUV' is the challenge based on visual cues.
Key Novelty
GPT-assisted Visual Instruction Data Generation & LLaVA Architecture
- Converts image-text pairs into instruction-following formats by prompting text-only GPT-4 with symbolic image representations (captions and bounding boxes)
- Connects a pre-trained visual encoder (CLIP) to a pre-trained LLM (Vicuna) via a simple linear projection layer
- Two-stage training: first aligns visual features to language embeddings, then fine-tunes end-to-end on complex multimodal instruction data
Architecture
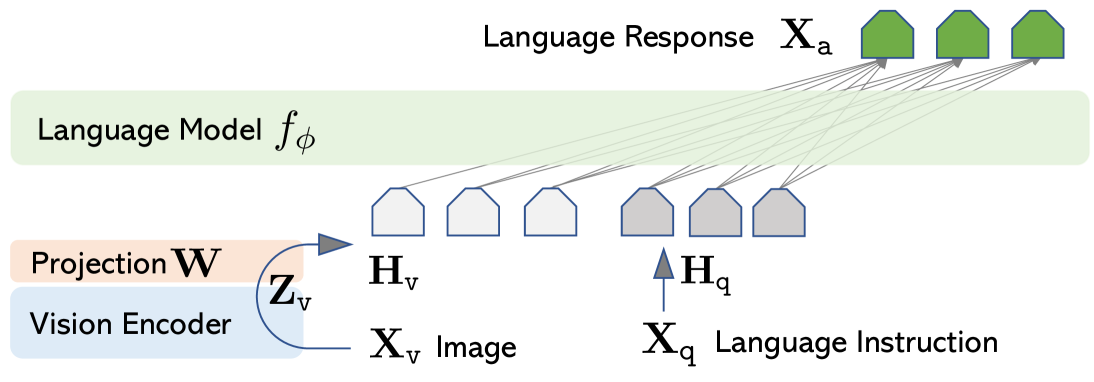
Network architecture of LLaVA and the data generation process
Evaluation Highlights
- Achieves 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset
- Establishes new state-of-the-art accuracy of 92.53% on ScienceQA when ensembled with GPT-4 (synergy)
- Demonstrates impressive zero-shot multimodal chat abilities, mimicking multimodal GPT-4 behaviors on unseen images
Breakthrough Assessment
9/10
Pioneered the 'visual instruction tuning' paradigm. LLaVA became a foundational baseline in the open-source community for building multimodal assistants.