📊 Experiments & Results
Evaluation Setup
Simulation (LIBERO benchmark) and Real-world (ALOHA robot) manipulation tasks.
Benchmarks:
- LIBERO (Simulation manipulation (Spatial, Object, Goal, Long suites))
- ALOHA Tasks (Real-world bimanual manipulation (folding, scooping, etc.)) [New]
Metrics:
- Success Rate (%)
- Inference Throughput (Hz / actions per second)
- Latency (ms)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| LIBERO benchmark results demonstrating OpenVLA-OFT's superiority over the base model and other baselines. | ||||
| LIBERO (Average across 4 suites) | Success Rate | 76.5 | 97.1 | +20.6 |
| LIBERO (Average across 4 suites) | Success Rate | 94.2 | 97.1 | +2.9 |
| Efficiency results showing massive speedups from the proposed recipe. | ||||
| Inference Speed | Throughput (Speedup Factor) | 1.0 | 26.0 | +25.0 |
| Real-world ALOHA robot evaluation comparing against strong baselines. | ||||
| ALOHA Tasks (Average) | Success Rate | Not reported in the paper as a single average number | Not reported in the paper as a single average number | Not reported in the paper |
Experiment Figures
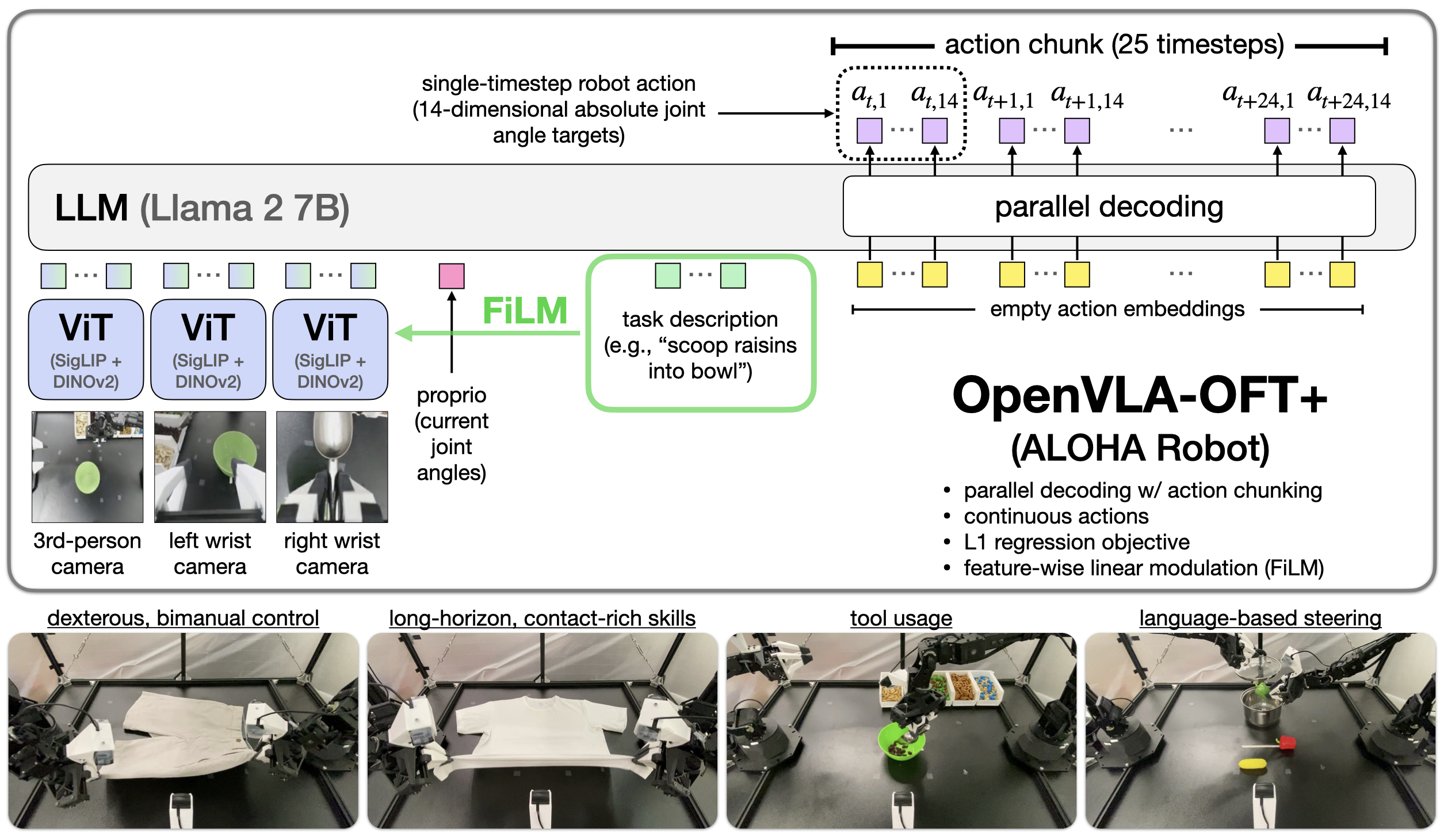
Real-world ALOHA tasks and performance summary.
Main Takeaways
- Parallel decoding with action chunking is strictly better than autoregressive generation for VLAs: it provides massive speedups (26-43x) and improves success rates.
- Continuous L1 regression is sufficient for high-performance fine-tuning; complex diffusion heads are not strictly necessary for SOTA results on these tasks.
- FiLM is critical for multi-view robot setups to prevent the model from ignoring language instructions due to visual spurious correlations.