📝 Paper Summary
Post-Training Quantization (PTQ)
Large Language Model Compression
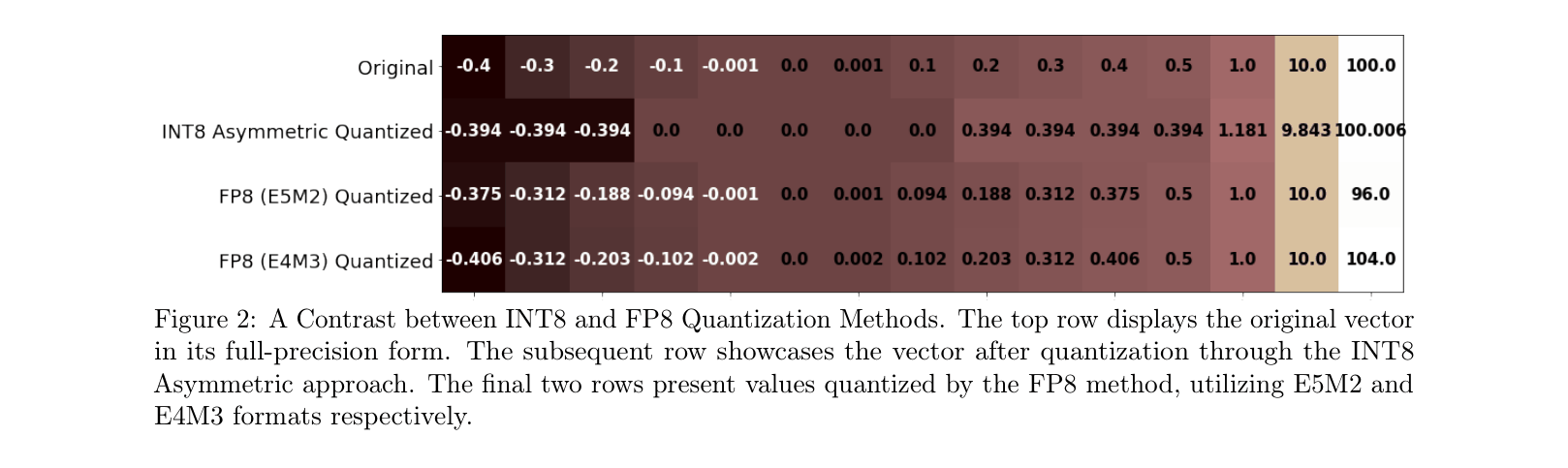
ZeroQuant-FP demonstrates that floating-point quantization (FP8 for activations, FP4 for weights) significantly outperforms integer equivalents for large language models, especially when handling outliers.
Core Problem
Standard integer quantization (INT8/INT4) degrades LLM performance because uniform quantization handles activation outliers poorly, skewing the representation of the main data distribution.
Why it matters:
- LLMs are computationally intensive, requiring quantization for efficient deployment on resource-limited hardware
- Existing integer methods often cause unacceptable accuracy drops (e.g., perplexity degradation >1.0) in larger models due to activation outliers
- New hardware like NVIDIA H100 supports FP8, creating an opportunity for more precise floating-point quantization formats
Concrete Example:
In the OPT-1.3B model, activation values in the 'fc2' module are heavily skewed by the ReLU operator, clustering around zero with large outliers. INT8 uniform quantization attempts to cover the outlier range, causing significant precision loss for the clustered small values, whereas FP8's dynamic exponent allocation captures both effectively.
Key Novelty
ZeroQuant-FP (W4A8 Floating-Point Quantization)
- Replaces integer quantization with floating-point formats (FP8 for activations, FP4 for weights) to better handle non-uniform distributions and outliers common in LLMs
- Proposes two scaling constraints (power-of-2 scaling) to efficiently cast FP4 weights to FP8 for computation without performance loss
- Integrates Low Rank Compensation (LoRC) to correct quantization errors in the weight matrix, particularly beneficial for smaller models
Architecture
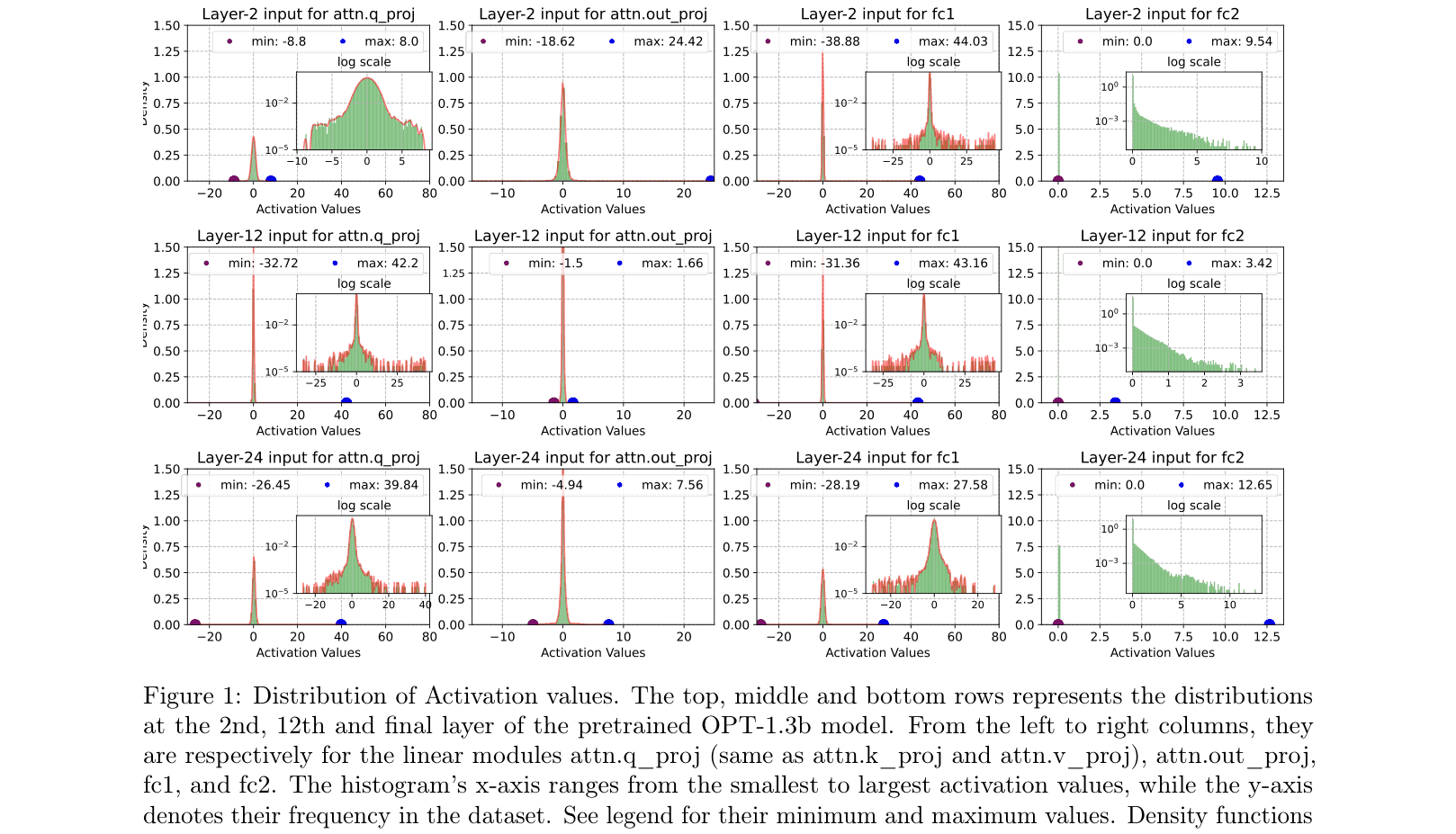
Histograms and density plots of activation values across different layers (2nd, 12th, 24th) and modules (Attention, MLP) of OPT-1.3b.
Evaluation Highlights
- FP8 activation outperforms INT8 activation on LLaMA-7b W4A8, reducing perplexity from 11.48 to 11.08 (lower is better)
- FP4 weights surpass INT4 weights; for LLaMA-7b W4A8, FP4 improves perplexity by 0.95 points (15.14 vs 16.09) compared to INT4
- W4A8 quantization with FP8 activation and FP4 weights achieves near-lossless performance compared to FP16 baselines for large models like LLaMA-30b (5.92 vs 5.79 PPL)
Breakthrough Assessment
8/10
Strong empirical evidence that FP formats are superior to INT for LLM quantization, timely aligned with H100 hardware capabilities. The FP4 weight findings are particularly promising for extreme compression.