📝 Paper Summary
Model Compression
Post-Training Quantization (PTQ)
Efficient Inference
TSPTQ-ViT enables fully quantized vision transformers by using dual scaling factors to handle the extreme value distributions in Softmax, GeLU, and LayerNorm without retraining.
Core Problem
Standard post-training quantization fails on Vision Transformers because activation functions (Softmax, GeLU) produce non-normal distributions and LayerNorm exhibits high channel-wise variance, causing severe accuracy loss.
Why it matters:
- Vision Transformers (ViTs) are computationally heavy (e.g., ViT-L has 64G FLOPs), making them unsuitable for resource-constrained edge devices without compression
- Existing quantization methods often skip sensitive layers (Softmax/LayerNorm) to preserve accuracy, preventing efficient fully integer-only inference
- Prior fully quantized attempts (like FQ-ViT) introduce high memory overhead or quantization errors for large values
Concrete Example:
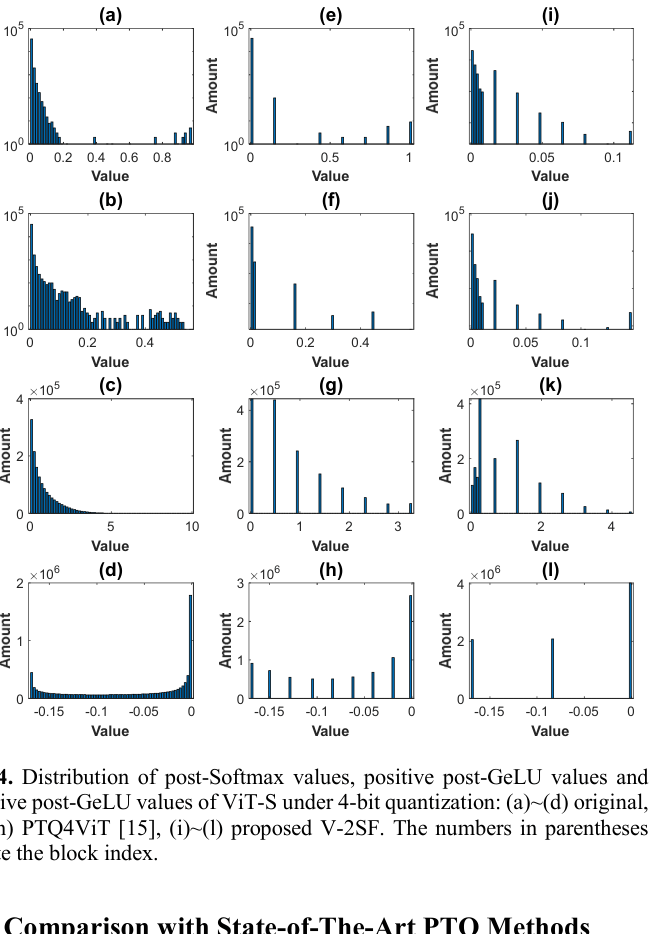
In LayerNorm inputs, the maximum value can be 40 times larger than the median. A single uniform scaling factor dominated by this outlier causes small values—which contain most of the information—to be quantized to zero, destroying accuracy.
Key Novelty
Two-Scaled Post-Training Quantization (TSPTQ)
- V-2SF (Value-Aware): Splits activations into two regions based on magnitude. Large values (outliers) keep the most significant bits, while small values (dense region) keep the least significant bits, effectively increasing precision.
- O-2SF (Outlier-Aware): Detects specific channels in LayerNorm that contain extreme values and assigns them a dedicated scaling factor, preventing them from distorting the quantization range of normal channels.
Architecture
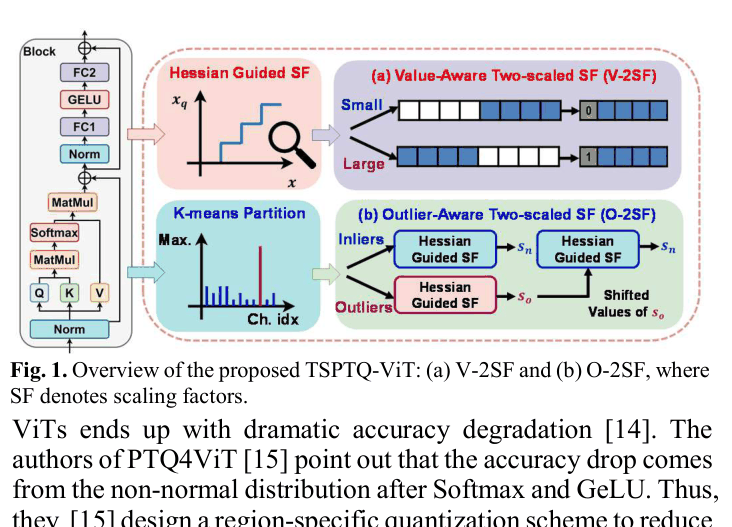
Overview of the TSPTQ-ViT scaling mechanisms: V-2SF for activations and O-2SF for LayerNorm inputs.
Evaluation Highlights
- Achieves <0.5% accuracy drop on ImageNet classification with 8-bit fully quantized ViT models compared to full-precision baselines
- Outperforms state-of-the-art FQ-ViT by +2.14% top-1 accuracy on Swin-B (8-bit quantization)
- Surpasses PTQ4ViT by ~1% accuracy on DeiT-T and DeiT-S under 6-bit quantization settings
Breakthrough Assessment
7/10
Strong engineering solution for fully quantized ViTs. Effectively addresses specific distribution bottlenecks (Softmax/GeLU/LayerNorm) with low overhead, outperforming existing PTQ methods significantly on larger models.