📝 Paper Summary
Model Compression
Vision Transformers (ViTs)
Post-Training Quantization (PTQ)
I&S-ViT enables accurate low-bit Vision Transformer quantization by introducing a shift-uniform-log2 quantizer to cover the full activation domain and a three-stage smooth optimization strategy to stabilize training.
Core Problem
Post-training quantization for ViTs suffers severe accuracy drops in low-bit settings (e.g., 3-bit) due to inefficient log2 quantizers and rugged loss landscapes caused by coarse-grained activation quantization.
Why it matters:
- Vision Transformers (ViTs) have dense computational costs, limiting industrial deployment without compression.
- Existing PTQ methods like RepQ-ViT suffer catastrophic failure in ultra-low bit scenarios (e.g., ~74% accuracy drop in 3-bit) due to optimization difficulties.
- Optimization-based PTQ methods successful in CNNs often overfit or fail to converge on ViT architectures due to the complex loss landscape of LayerNorm/Softmax.
Concrete Example:
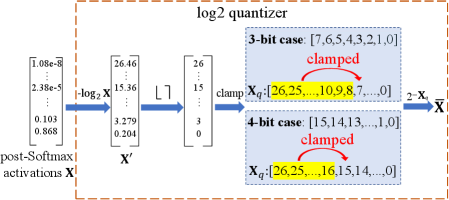
For post-Softmax activations in range [1.08e-8, 0.868], a standard 3-bit log2 quantizer clamps the rounded segment [8, 26] entirely to 7, failing to represent a large portion of the domain ('quantization inefficiency').
Key Novelty
Inclusive Quantizer & Stable Optimization Strategy (I&S-ViT)
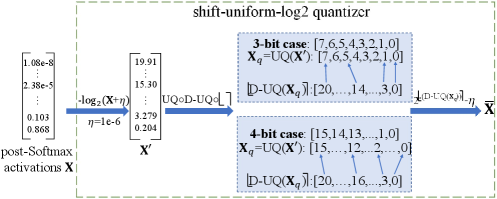
- **Shift-Uniform-Log2 Quantizer (SULQ):** Adds a shift bias before log2 transformation, then applies uniform quantization. This allows the quantizer to encompass the entire input domain inclusively, unlike standard log2 which truncates large segments.
- **Smooth Optimization Strategy (SOS):** A 3-stage training process that starts with a smooth loss landscape (FP weights + channel-wise activations) and gradually transitions to the target constraints via lossless reparameterization.
Architecture
Conceptual flow of the SULQ quantizer: Input X -> Add Shift Bias -> Log2 -> Uniform Quantization -> Round -> Output.
Evaluation Highlights
- Elevates the performance of 3-bit ViT-B (Vision Transformer Base) by 50.68% compared to prior methods like RepQ-ViT.
- Successfully recovers accuracy in 4-bit scenarios where baselines like RepQ-ViT typically suffer ~10% accuracy drops.
- Demonstrates stability in optimization where standard CNN-based PTQ methods result in overfitting or divergence on ViTs.
Breakthrough Assessment
8/10
Addresses a critical failure mode of ViT quantization (3-bit collapse) with a theoretically grounded method (fixing domain coverage and landscape roughness). The reported +50% gain in 3-bit is substantial.