📝 Paper Summary
Post-Training Quantization (PTQ)
Large Language Models (LLMs)
Efficient Inference
FPTQ enables efficient W4A8 inference for LLMs by using logarithmic equalization to suppress activation outliers and a fine-grained strategy, achieving FP16-level accuracy without fine-tuning.
Core Problem
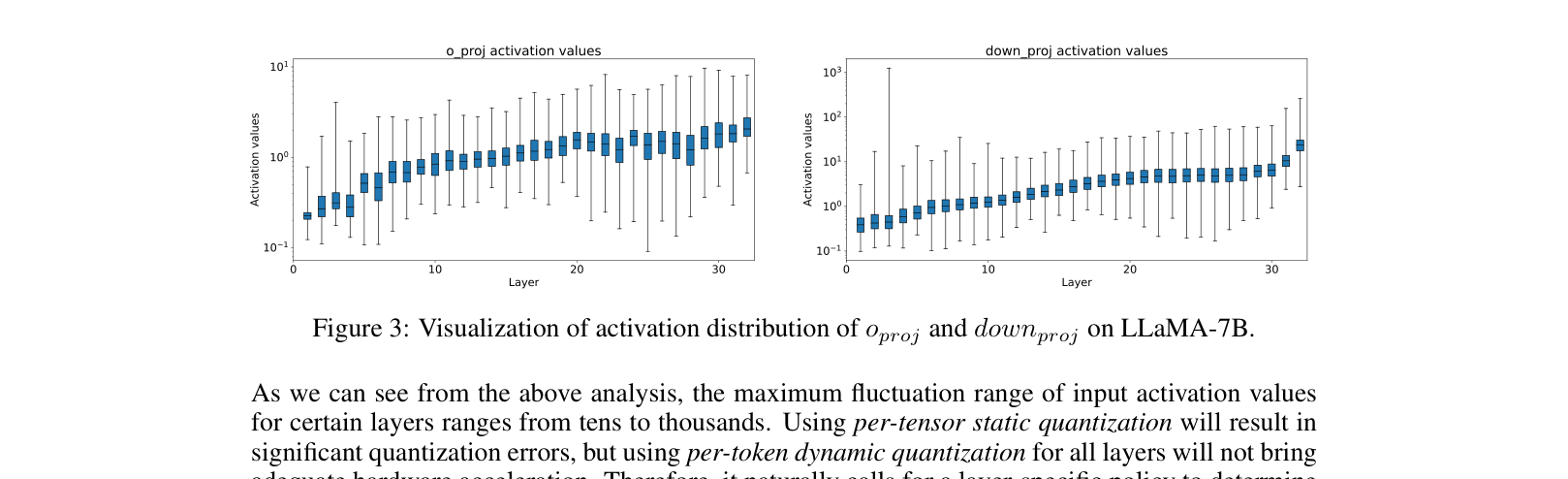
W4A8 quantization theoretically optimizes both compute-bound and memory-bound inference stages, but standard methods cause severe accuracy collapse in LLMs due to massive activation outliers.
Why it matters:
- Existing recipes compromise: W8A8 (SmoothQuant) is slow at context decoding, while W4A16 (GPTQ) is slow at context decoding; only W4A8 accelerates both stages.
- LLMs typically contain outlier activation values that destroy quantization precision when mapped linearly to low-bit integers.
- Deploying massive models like LLaMA-2-70B on resource-constrained devices requires reducing both memory footprint and compute latency simultaneously.
Concrete Example:
In LLaMA-7B, the 'down_proj' layer has activation values spanning thousands, whereas 'o_proj' is compact. Applying a uniform static quantization to 'down_proj' clips signal or destroys resolution, causing the model to output gibberish.
Key Novelty
Fine-grained Post-Training Quantization (FPTQ) with Logarithmic Activation Equalization
- Applies a 'Logarithmic Activation Equalization' (LAE) to non-linearly squash massive activation outliers (like pressing down on a spike) so the distribution fits into 8-bit integers.
- Uses a layer-wise strategy: 'easy' layers get fast static quantization, while 'hard' layers with outliers get equalization or dynamic quantization to preserve accuracy.
Architecture
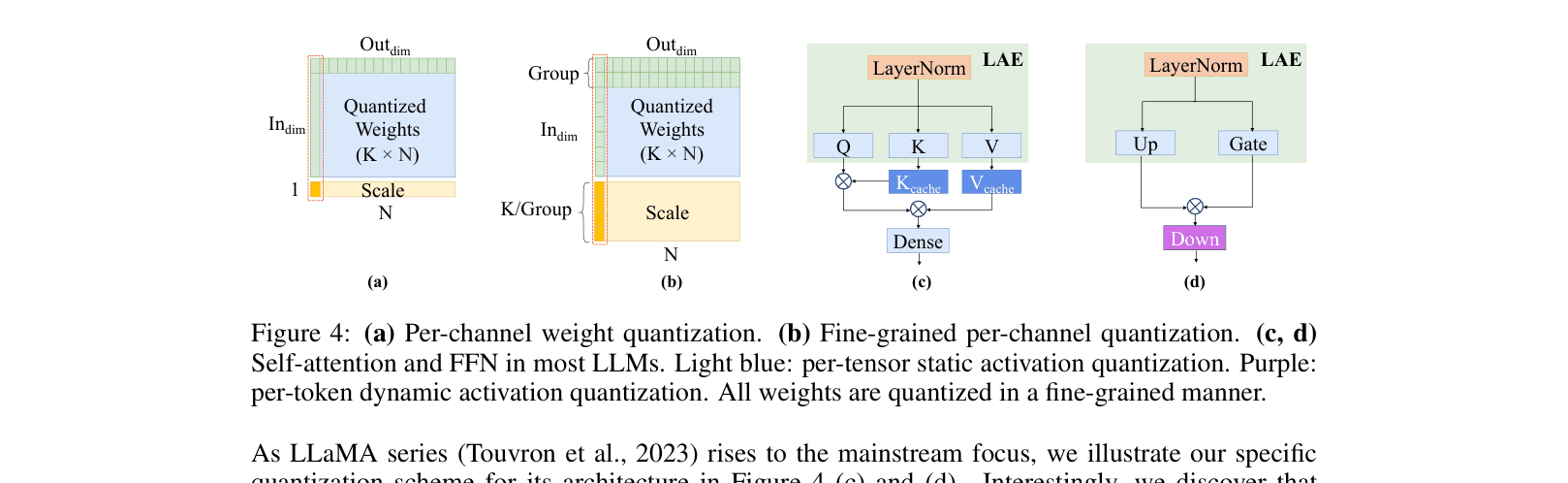
The FPTQ quantization scheme for Transformer blocks, highlighting where Logarithmic Activation Equalization (LAE) is applied.
Evaluation Highlights
- Achieves 78.71% accuracy on LAMBADA with LLaMA-2-70B using W4A8, retaining 98.9% of the original FP16 performance (79.57%).
- Outperforms LLM-QAT (a computationally expensive training-based method) on LLaMA-13B Common Sense QA, scoring 76.81% vs 75.05%.
- Matches the widely used SmoothQuant (W8A8) performance on Common Sense QA for LLaMA-7B (73.42% vs 74.12%) while using half the weight memory.
Breakthrough Assessment
8/10
Successfully demonstrates W4A8 quantization for large models (up to 70B) without retraining, unlocking simultaneous acceleration of prefill and decoding phases. Significant practical value for deployment.