📝 Paper Summary
Post-Training Quantization (PTQ)
Model Compression
A post-training quantization algorithm that automatically assigns layer-specific bit-widths by measuring sensitivity via Signal-to-Quantization-Noise-Ratio (SQNR) and performing a greedy search to maximize accuracy under efficiency budgets.
Core Problem
Assigning the same bit-width to all layers (homogeneous quantization) is inefficient because layers vary in sensitivity, but existing mixed-precision methods require expensive retraining or complex hyperparameter tuning.
Why it matters:
- Standard quantization (e.g., 8-bit) often degrades accuracy significantly for compact networks like MobileNetV3 or Transformers like BERT/ViT.
- Existing mixed-precision solutions often require access to full labeled training datasets, which may not be available during deployment due to privacy or storage constraints.
- Manual selection of bit-widths for each layer is intractable given the vast search space of deep neural networks.
Concrete Example:
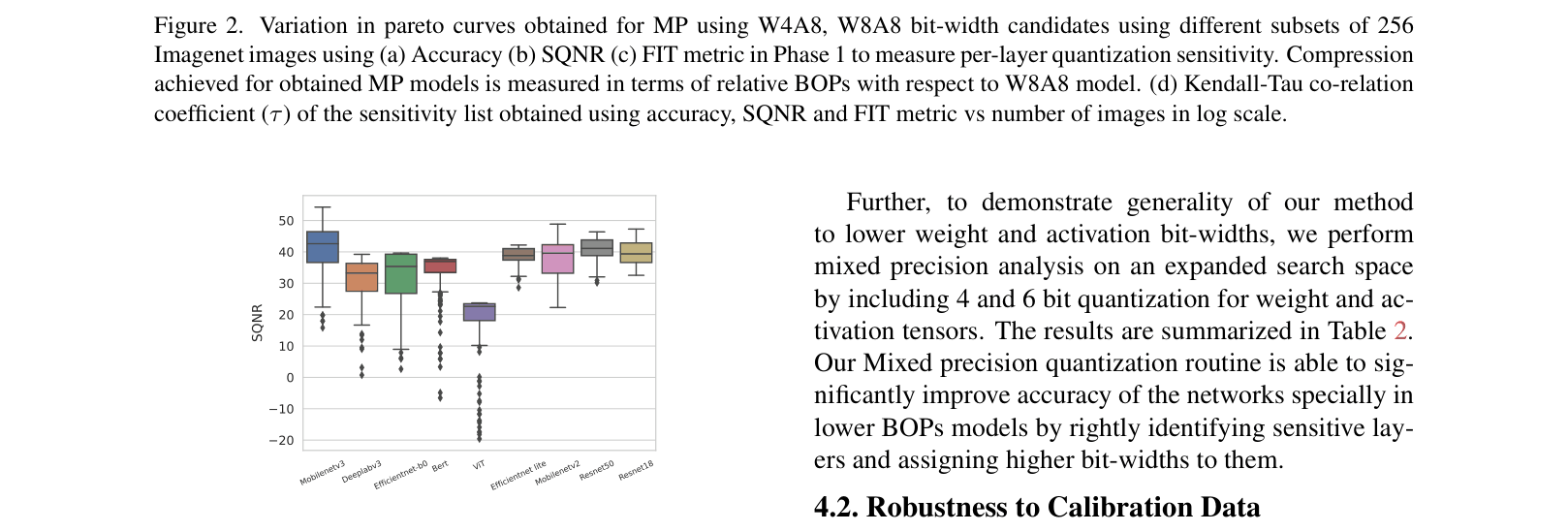
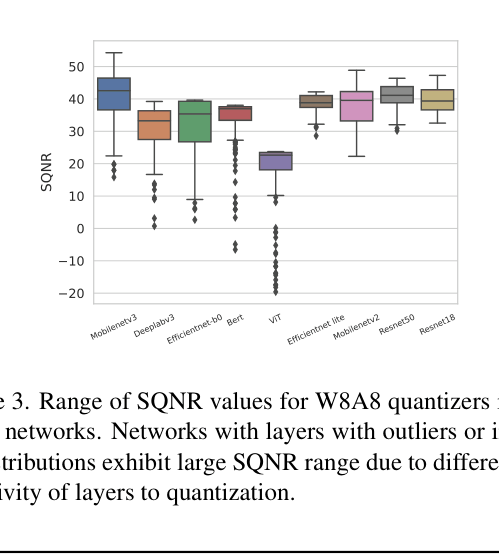
In a Vision Transformer (ViT), standard W8A8 (8-bit weights/activations) quantization causes accuracy to crash to 18.83% due to outliers. The proposed mixed precision algorithm identifies sensitive layers, keeps them at higher precision, and recovers accuracy to 80.58%.
Key Novelty
SQNR-based Greedy Pareto Search
- Uses Signal-to-Quantization-Noise-Ratio (SQNR) as a fast, label-free proxy to measure how much each layer's output is corrupted by quantization noise.
- Employing a greedy strategy that starts with the model at maximum precision and iteratively lowers the bit-width of the 'least sensitive' layer (highest SQNR) until an efficiency or accuracy budget is hit.
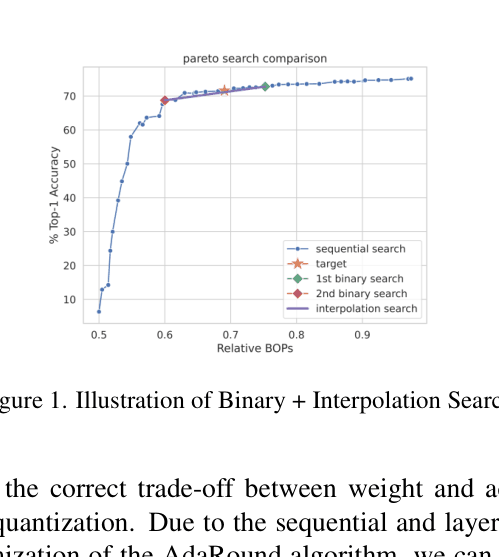
- Optimizes the search speed using binary and interpolation search to find the optimal configuration on the Pareto frontier in logarithmic time.
Architecture
Pseudocode of the two-phase algorithm: Sensitivity Analysis followed by Greedy Search.
Evaluation Highlights
- +2.90% Top-1 accuracy improvement on MobileNetV3 compared to standard W8A8 (8-bit weights/activations) fixed precision.
- Recovers BERT (MNLI) accuracy from 74.13% (W8A8) to 82.97% (Mixed Precision), nearly matching the FP32 baseline of 84.40%.
- Reduces search time for mixed precision configurations from 14.1 hours (sequential search) to 0.4 hours (binary + interpolation search) for MobileNetV3.
Breakthrough Assessment
8/10
Provides a highly practical, data-efficient, and hyperparameter-free solution to a critical deployment problem. While not a new architecture, its ability to fix broken quantized models (like ViT/BERT) without retraining is significant for industry adoption.