📝 Paper Summary
Model Compression
Efficient Inference
This paper demonstrates that FP8 formats outperform INT8 for post-training quantization by providing better dynamic range for outliers in NLP models and higher precision for computer vision tasks.
Core Problem
INT8 quantization struggles with limited dynamic range, causing significant accuracy loss in modern deep learning models (especially LLMs) due to large outliers in activations, often requiring complex calibration or fallback to higher precision.
Why it matters:
- Large Language Models (LLMs) contain massive outliers (e.g., in LayerNorm) that break standard integer quantization schemes.
- Current INT8 methods often fail to maintain accuracy without complex, hardware-unfriendly workarounds like mixed-precision or outlier suppression.
- A significant percentage of modern workloads cannot be quantized to INT8 effectively, limiting deployment efficiency on resource-constrained devices.
Concrete Example:
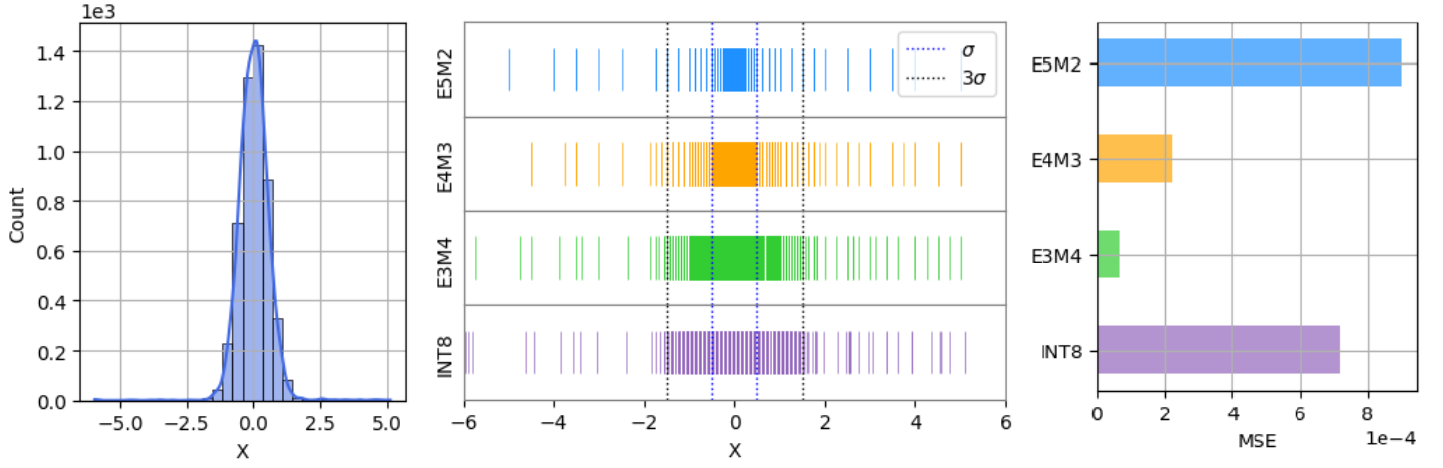
In INT8 quantization, a single large outlier value stretches the quantization grid, reducing the precision available for the vast majority of small values near zero. The paper shows that for Stable Diffusion, INT8 produces image artifacts (e.g., loss of detail on an astronaut's suit), whereas FP8 formats generate smooth, high-quality images comparable to the original.
Key Novelty
Unified FP8 Post-Training Quantization Workflow
- Evaluates three FP8 variants (E5M2, E4M3, E3M4) to balance dynamic range versus precision across 75+ diverse models.
- Introduces a mixed-precision strategy assigning different FP8 formats to weights (precision-bound) and activations (range-bound) based on their specific distributions.
- Extends quantization to sensitive operations usually left in float32, such as LayerNorm and BatchNorm, which FP8 can handle due to its non-uniform grid.
Architecture
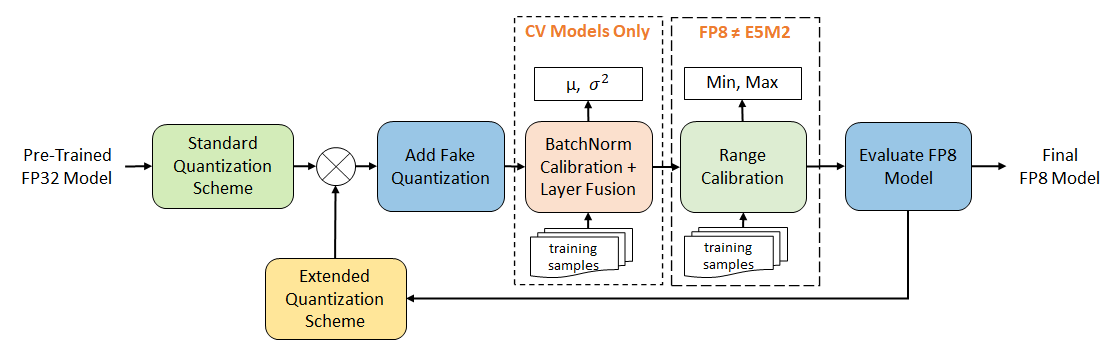
The Post-Training FP8 Quantization Workflow.
Evaluation Highlights
- FP8 achieves 92.64% workload coverage (models meeting 1% accuracy loss threshold) compared to only 65.87% for INT8 across 75 models.
- E4M3 is identified as the optimal format for NLP models (96.32% coverage), while E3M4 marginally outperforms on Computer Vision (78.95% coverage).
- FP8 quantization enables the quantization of LayerNorm and BatchNorm layers without accuracy loss, unlike INT8 which typically requires keeping them in FP32.
Breakthrough Assessment
7/10
Strong empirical evidence across a massive set of models (75+) establishing FP8 as a superior standard over INT8 for future hardware. While the methods are standard PTQ techniques applied to new formats, the scale and analysis of the E4M3/E3M4 trade-offs are significant.