📝 Paper Summary
Post-Training Quantization (PTQ)
Neural Network Compression
Large Language Model Quantization
FlexRound optimizes post-training quantization by using element-wise division for rounding, which leverages the reciprocal rule of derivatives to automatically assign more flexible quantization grids to larger, more important weights.
Core Problem
Existing PTQ rounding schemes (like AdaRound) rely on element-wise addition, which restricts weights to be rounded only to their nearest neighbors and fails to inherently prioritize updating important high-magnitude weights.
Why it matters:
- Quantization-Aware Training (QAT) is resource-intensive and requires full datasets, which may be unavailable due to privacy or legacy issues, making effective PTQ crucial.
- Current PTQ methods suffer performance degradation on compact architectures (MobileNetV2) or high-bit settings because they enforce rigid rounding constraints.
- Weights with larger magnitudes are typically more important for network performance, but standard rounding-to-nearest treats all weights equally regardless of their impact.
Concrete Example:
In MobileNetV2, weights with absolute values larger than 1.0 are critical. Standard adaptive rounding restricts these weights to the two nearest discrete values. FlexRound allows 12.8% of weights in the first convolutional block to shift to grids further away, preserving accuracy where rigid rounding fails.
Key Novelty
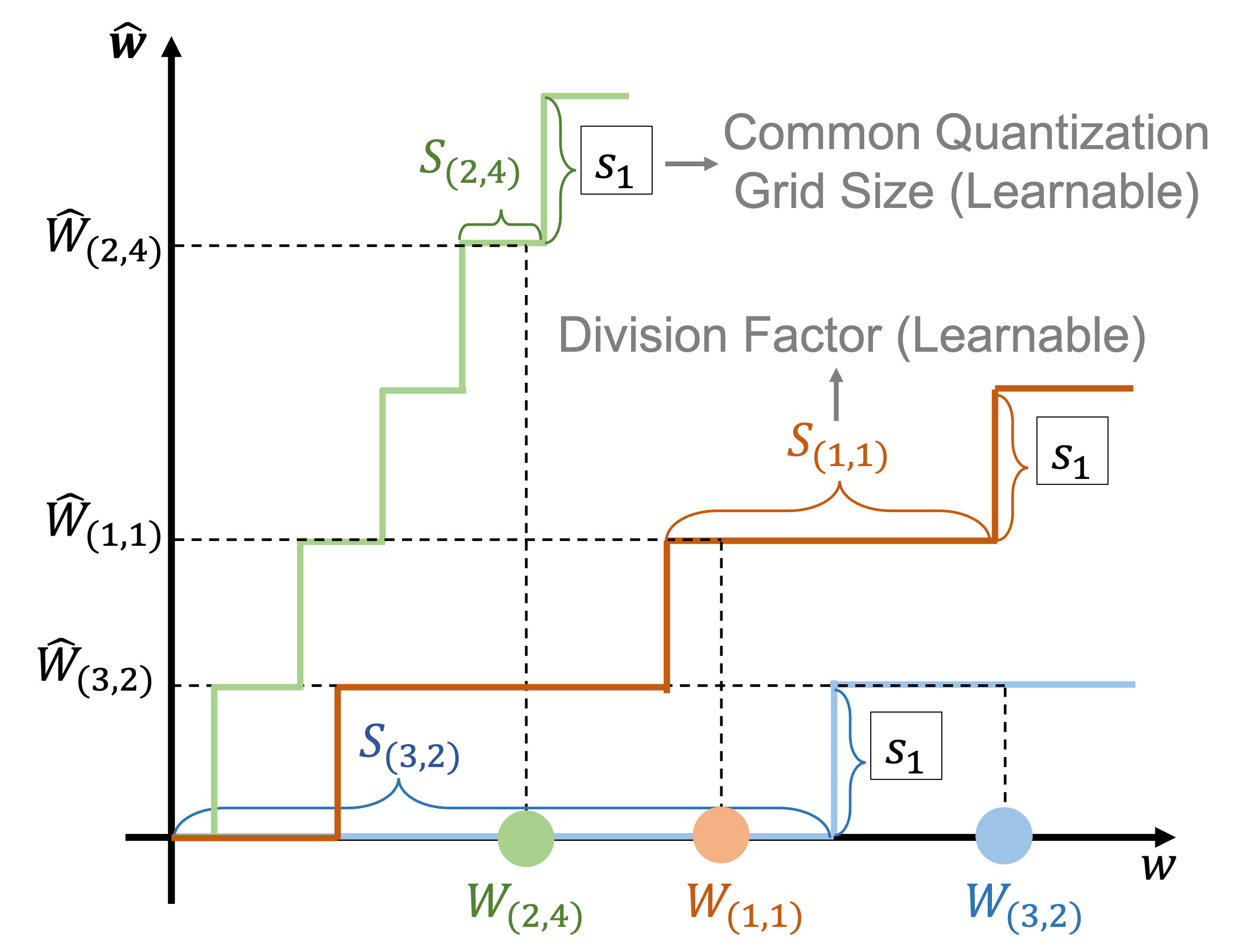
Element-wise Division-based Rounding
- Replaces the standard additive rounding formulation with a division-based one ($W/S$), allowing the system to jointly learn a common grid size and individual weight scales.
- Exploits the reciprocal rule of derivatives: the gradient for the scale parameter is proportional to the weight's magnitude, causing larger (more important) weights to receive larger updates and more flexible rounding.
Architecture
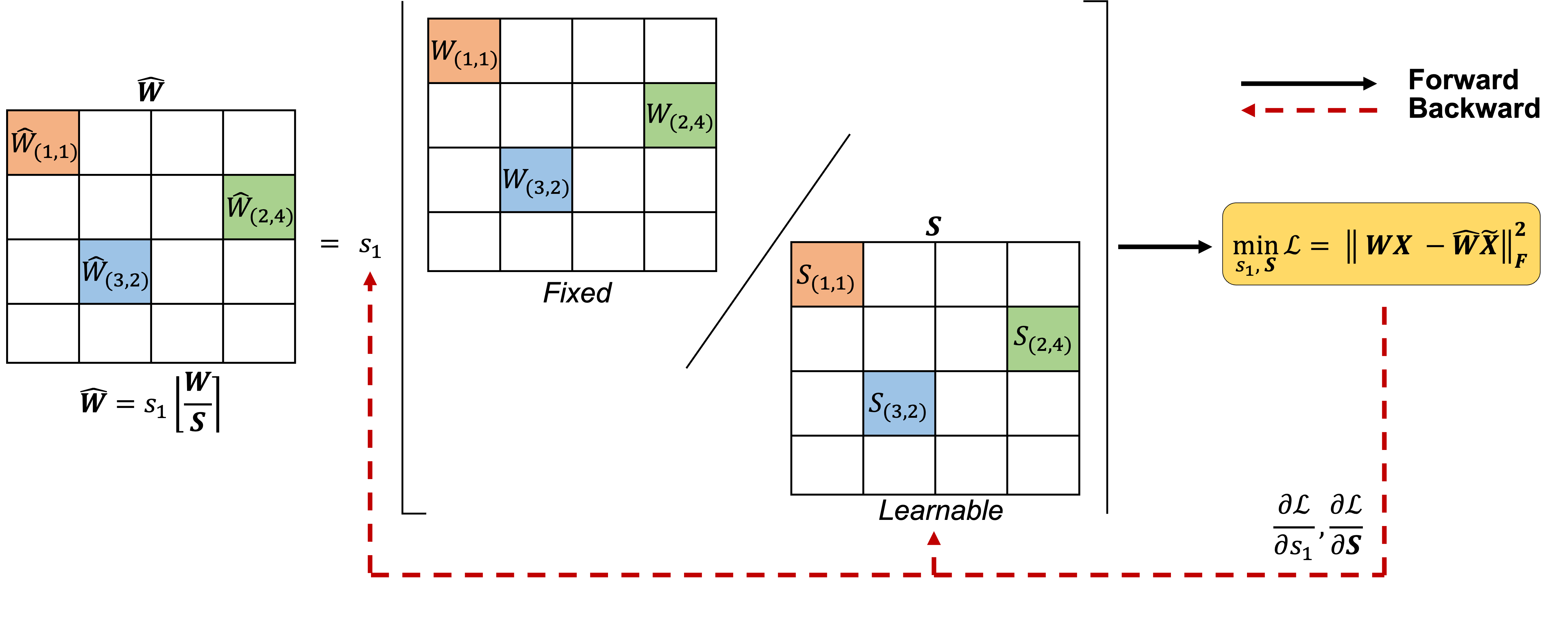
Overview of the FlexRound procedure within the PTQ pipeline.
Evaluation Highlights
- 12.8% of weights in the first block of MobileNetV2 are rounded 'aggressively' (deviating more than one grid step), demonstrating high flexibility for sensitive, compact models.
- Only 1.5% of weights in ResNet-18 are rounded aggressively, showing the method inherently adapts to the model's tolerance (ResNet is less sensitive than MobileNet).
- Demonstrates negligible performance impact on LLaMA compared to half-precision baselines using block-by-block reconstruction (qualitative result from abstract).
Breakthrough Assessment
7/10
Proposes a mathematically motivated change (division vs. addition) that intuitively aligns gradient magnitude with weight importance. It addresses a specific limitation in PTQ rigidity, particularly for LLMs and compact models.