📝 Paper Summary
Model Quantization
Hardware Acceleration
Vision Transformers
P2-ViT enables efficient, fully quantized Vision Transformers by replacing floating-point scaling factors with Power-of-Two factors via dedicated algorithms and a tailored hardware accelerator.
Core Problem
Existing fully quantized Vision Transformers retain floating-point scaling factors, requiring costly floating-point operations for re-quantization that hinder integer-only inference and limit hardware efficiency.
Why it matters:
- Floating-point re-quantization overheads are non-negligible, consuming significant energy and area on hardware.
- Current accelerators focus on matrix multiplications but overlook the re-quantization bottleneck, limiting the potential for layer fusion and pipeline processing.
- Deploying heavy ViT models on resource-constrained edge devices requires both memory reduction and computational speedup without accuracy loss.
Concrete Example:
In standard FQ-ViT, even if weights/activations are integers, the scaling factor 'S' is a float (e.g., 5.2). Re-quantization requires multiplying by 5.2, which is a floating-point operation. P2-ViT converts this to a Power-of-Two shift (e.g., shift by 2 and 3), replacing complex multipliers with simple bit-shifters.
Key Novelty
Power-of-Two (PoT) Scaling Factors & Chunk-Based Accelerator
- Replaces floating-point scaling factors with Power-of-Two (PoT) values using an adaptive rounding search that minimizes activation quantization error rather than just scaling factor error.
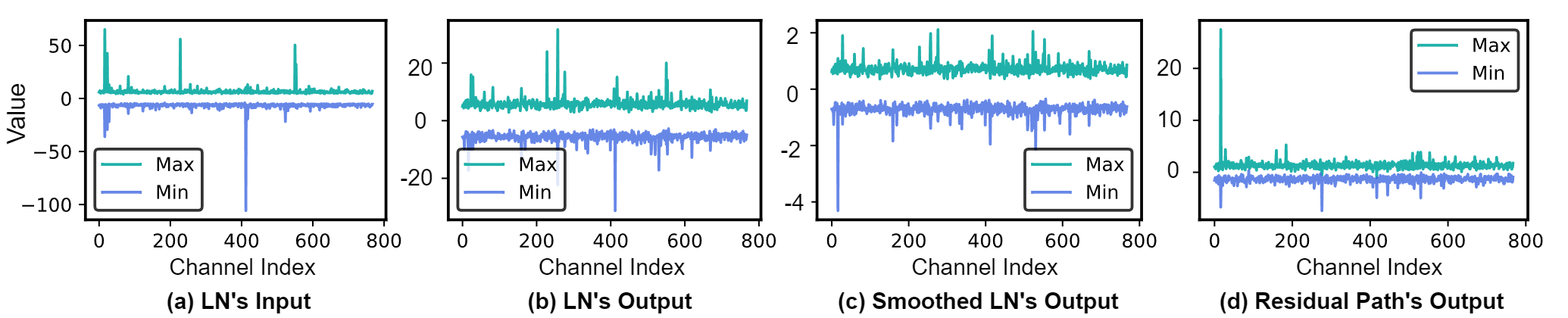
- Introduces 'PoT-Aware Smoothing' to migrate outliers from sensitive activations (like LayerNorm outputs) to weights, enabling hardware-friendly channel-wise quantization via bit-shifts.
- Designs a dedicated hardware accelerator with specific 'chunks' (sub-processors) for different operations and a row-stationary dataflow to pipeline the now-efficient re-quantization steps.
Architecture
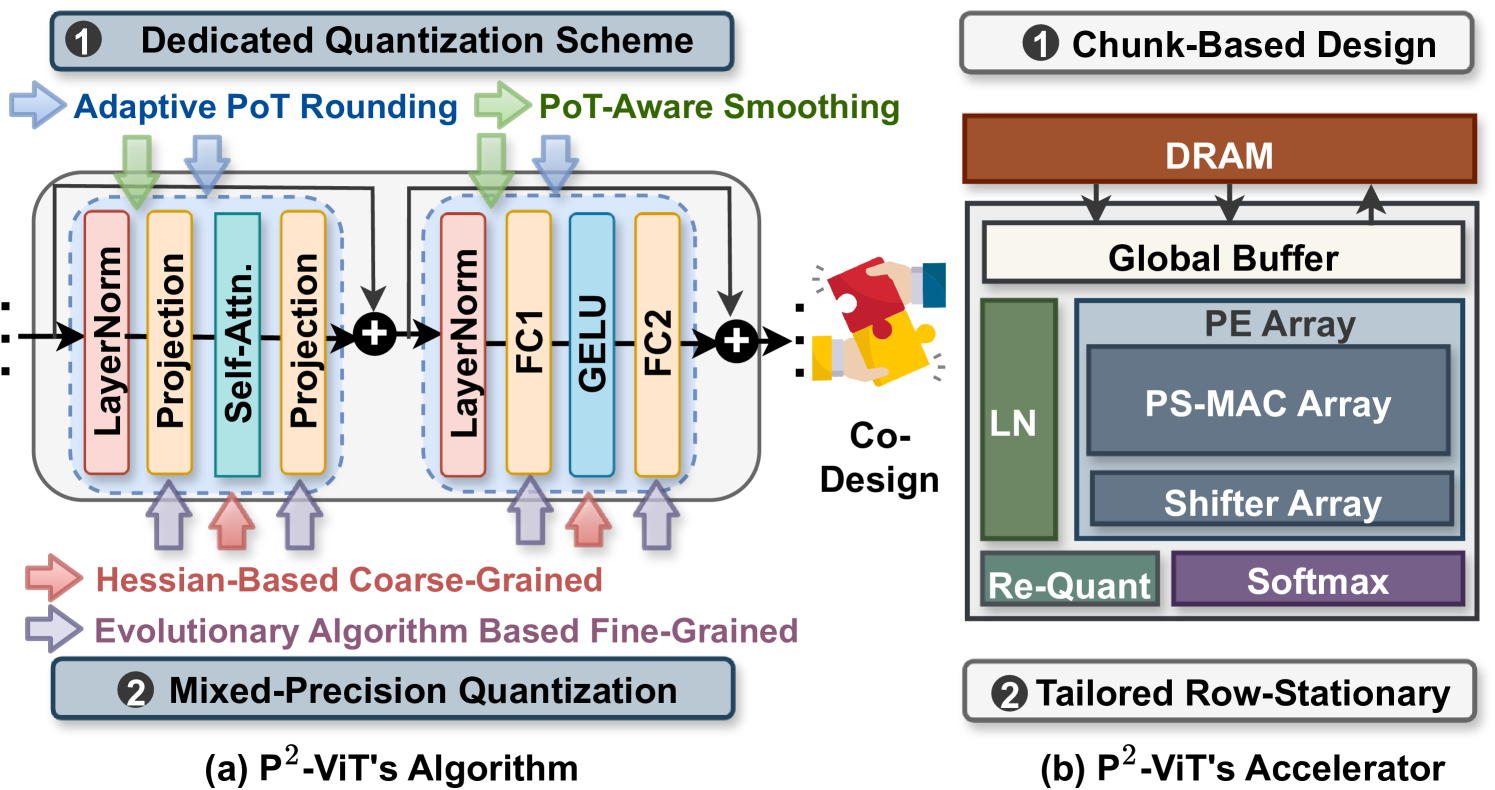
Overview of the P2-ViT framework including both the software quantization flow and the hardware accelerator architecture.
Evaluation Highlights
- Achieves up to 10.1x speedup and 36.8x energy saving over GPU Turing Tensor Cores for ViT inference.
- Offers up to 1.84x higher computation utilization efficiency compared to SOTA quantization-based ViT accelerators.
- Maintains accuracy comparable to floating-point scaling factor counterparts (e.g., 81.39% Top-1 on ImageNet for ViT-B, minimal drop from 81.64% baseline).
Breakthrough Assessment
8/10
Strong hardware-algorithm co-design. Successfully addresses the overlooked bottleneck of re-quantization in ViTs, enabling true integer-only inference with significant efficiency gains and minimal accuracy loss.