📝 Paper Summary
Multilingual Representation Learning
Cross-lingual Transfer
The paper proposes aligning representations across different scripts in multilingual models by post-training with transliterated data using combined masked language modeling, sequence-level contrastive learning, and token-level alignment objectives.
Core Problem
Multilingual models struggle to transfer knowledge between languages written in different scripts (the 'script barrier') because their embeddings are disjoint, even when languages are linguistically related.
Why it matters:
- Low-resource languages often perform poorly in transfer tasks solely due to script differences
- Existing alignment methods require parallel data (dictionaries/translations), which is scarce for many low-resource languages
- Token representations from different scripts can be linearly separated, indicating a lack of a common representation space
Concrete Example:
A model trained on high-resource English (Latin script) may fail to transfer performance to Amharic (Ge'ez script) or Farsi (Arabic script) despite shared vocabulary or areal features, because the model treats the different scripts as unrelated symbols.
Key Novelty
Transliteration-based Post-Training Alignment (PPA)
- Uses rule-based transliteration (Uroman) to convert monolingual data into Latin script, creating pseudo-parallel data without needing translation dictionaries
- Combines three distinct objectives: standard Masked Language Modeling, Sequence-Level Contrastive Learning (aligning sentence embeddings), and Token-Level Alignment (aligning word embeddings via concatenation)
- Applies alignment at both sequence and token levels simultaneously, addressing limitations of prior work that focused on only one or relied on English-centric transfer
Architecture
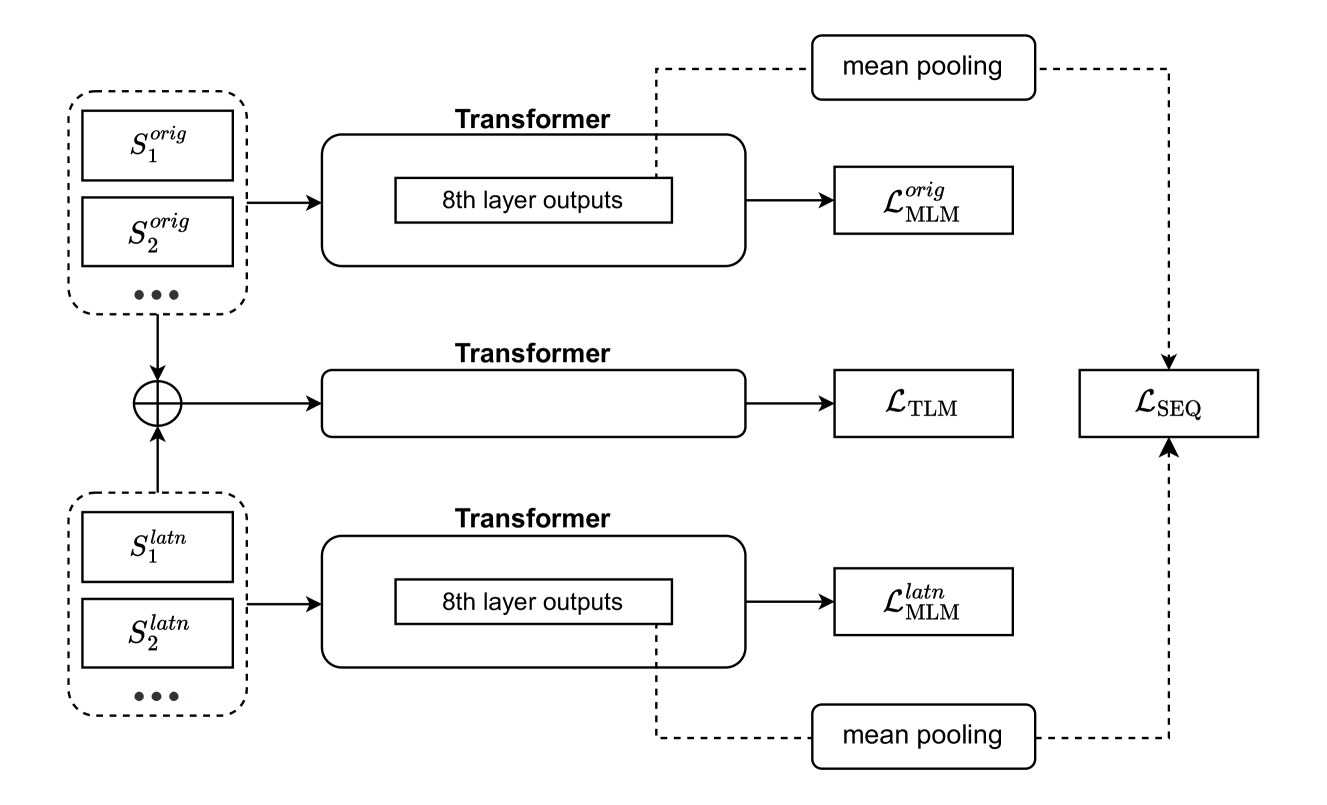
Conceptual illustration of the Transliteration-Based Post-Training Alignment method
Breakthrough Assessment
7/10
Proposed method effectively addresses the script barrier without expensive parallel data. The combination of sequence and token-level alignment via transliteration is a logical and potentially high-impact extension of prior work.