📝 Paper Summary
Model Compression
Neural Network Pruning
UniPTS enables high-performance neural network pruning using only small calibration datasets by unifying a dynamic global distillation objective, an evolutionary search for sparsity distribution, and dynamic structure updates.
Core Problem
Existing Post-Training Sparsity (PTS) methods suffer severe performance collapse at high sparsity ratios (e.g., 90%) because they rely on layer-wise error minimization that accumulates bias and cannot effectively recover weights using limited data.
Why it matters:
- Standard pruning requires retraining on the full dataset, which is often computationally prohibitive or impossible due to data privacy/accessibility constraints
- Current PTS methods like POT degrade to random-level performance at high compression rates (e.g., 90%), rendering them useless for extreme model compression
- Closing the gap between full-data retraining and post-training compression is critical for deploying efficient AI on resource-constrained edge devices
Concrete Example:
When pruning a ResNet-50 model to 90% sparsity on ImageNet using the standard POT method, the accuracy drops to 3.9% (random guessing level), whereas UniPTS maintains 68.6% accuracy using the same limited calibration data.
Key Novelty
Unified Framework for Post-Training Sparsity (UniPTS)
- Replaces static layer-wise error minimization with a **Base-Decayed Sparsity Objective**, where the distillation loss intensity adapts over time to prevent vanishing gradients and ensure efficient knowledge transfer
- Uses a **Reducing-Regrowing Evolutionary Search** to find optimal layer-wise sparsity ratios by temporarily over-pruning and then regrowing weights, preventing overfitting to the small calibration set
- Adapts **Dynamic Sparsity Training (DST)** for the data-limited setting by updating the sparse structure iteration-wise (not periodically) and decaying pruned weight magnitudes to stabilize training
Architecture
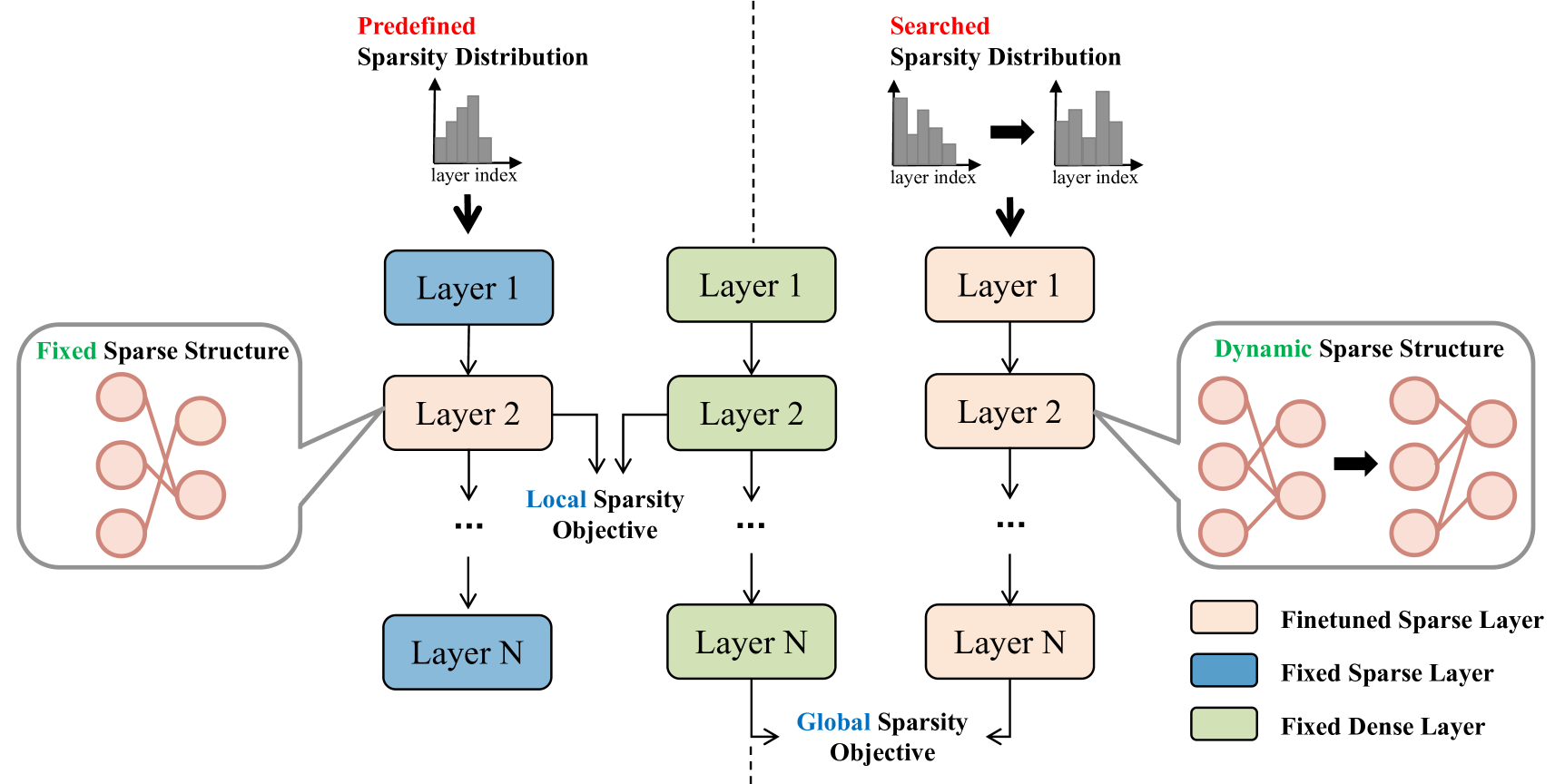
A schematic of the UniPTS framework comparing it to traditional sparsity methods. It illustrates the three main components: Sparsity Objective (Global KL), Sparsity Distribution (Search), and Sparsity Structure (Dynamic Training).
Evaluation Highlights
- +64.7% accuracy improvement over POT (state-of-the-art PTS baseline) when pruning ResNet-50 to 90% sparsity on ImageNet (3.9% → 68.6%)
- Achieves these gains while using less training time than the baseline POT method
- Successfully prevents the performance collapse typical of PTS methods at high sparsity rates
Breakthrough Assessment
8/10
The method dramatically fixes the 'collapse to random' failure mode of post-training sparsity at high compression rates, recovering over 60% accuracy where baselines fail completely. This is a significant practical advance for data-limited model compression.