📝 Paper Summary
Hallucination suppression
Modularized RAG pipeline
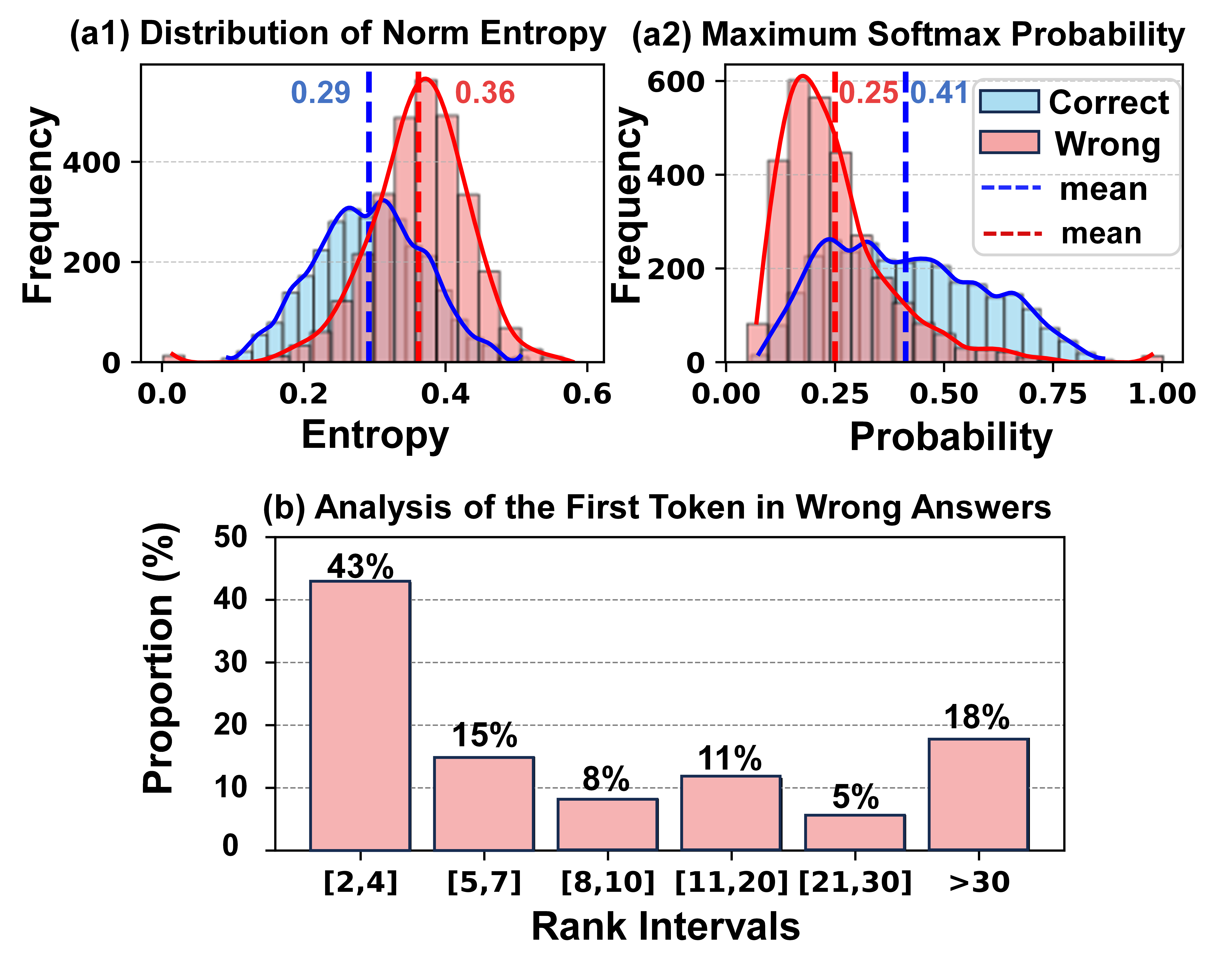
DAGCD mitigates context faithfulness hallucinations by using attention distributions to identify utilized context tokens and boosting their probability when the model exhibits high uncertainty.
Core Problem
RAG models often suffer from 'Context Faithfulness Hallucinations,' where they ignore retrieved information and generate unfaithful answers despite having the correct context available.
Why it matters:
- Hallucinations undermine trust in RAG systems, especially in critical domains where factual accuracy is paramount.
- Existing decoding methods like CAD and COIECD require multiple decoding passes, increasing computational cost, or lack interpretability regarding why context is ignored.
Concrete Example:
In a QA scenario, a model might retrieve a document stating 'The team was formerly known as X,' but still generate 'The team was formerly known as Y.' The paper shows the model actually attends to 'X' (ranks it in top-10) but fails to assign it the highest probability due to low confidence.
Key Novelty
Dynamic Attention-Guided Context Decoding (DAGCD)
- Detects which context tokens the model is internally 'looking at' using a classifier trained on attention weights (Attention Ratio).
- Dynamically boosts the probability of these utilized context tokens during generation, but only when the model's intrinsic uncertainty (entropy) is high.
- Operates in a single decoding pass without requiring external models or multiple forward passes, unlike contrastive decoding methods.
Architecture
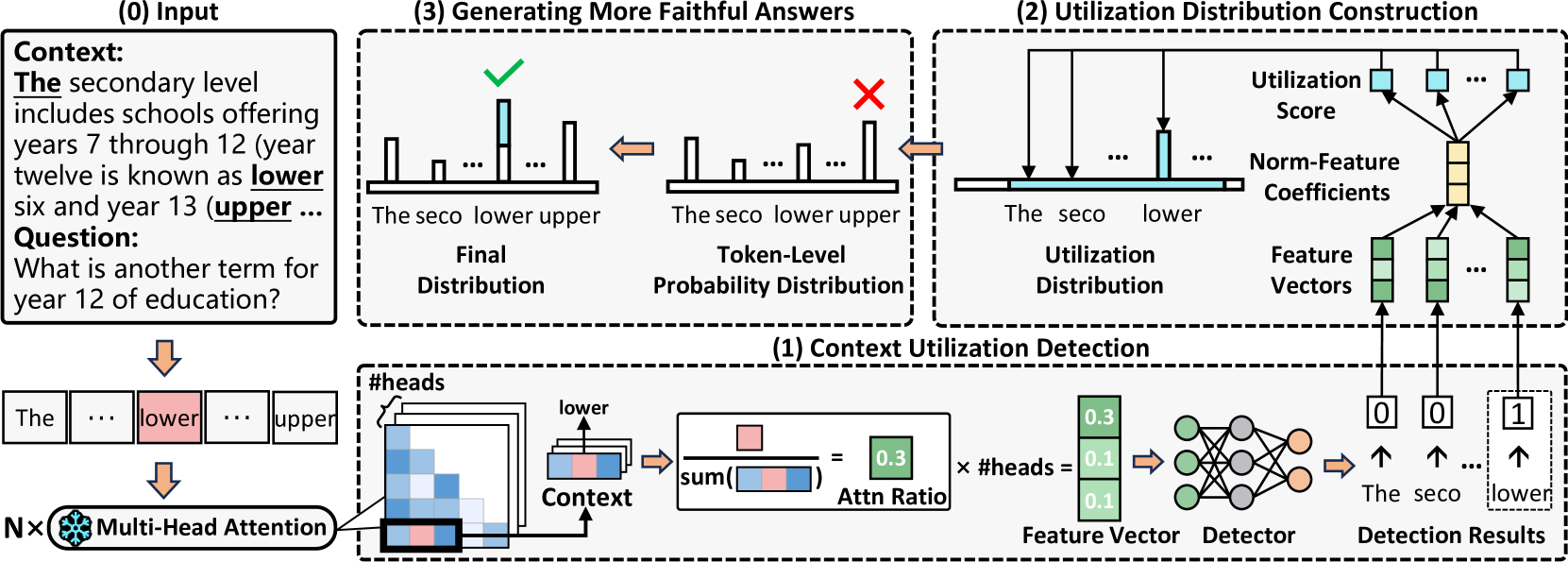
The workflow of Dynamic Attention-Guided Context Decoding (DAGCD).
Evaluation Highlights
- Achieves up to +17.67% improvement in Exact Match (EM) over greedy decoding on pre-trained Llama-2-7B across 6 QA datasets.
- Outperforms strong baselines like CAD (Contrastive Decoding) and DoLa while being more computationally efficient (single-pass).
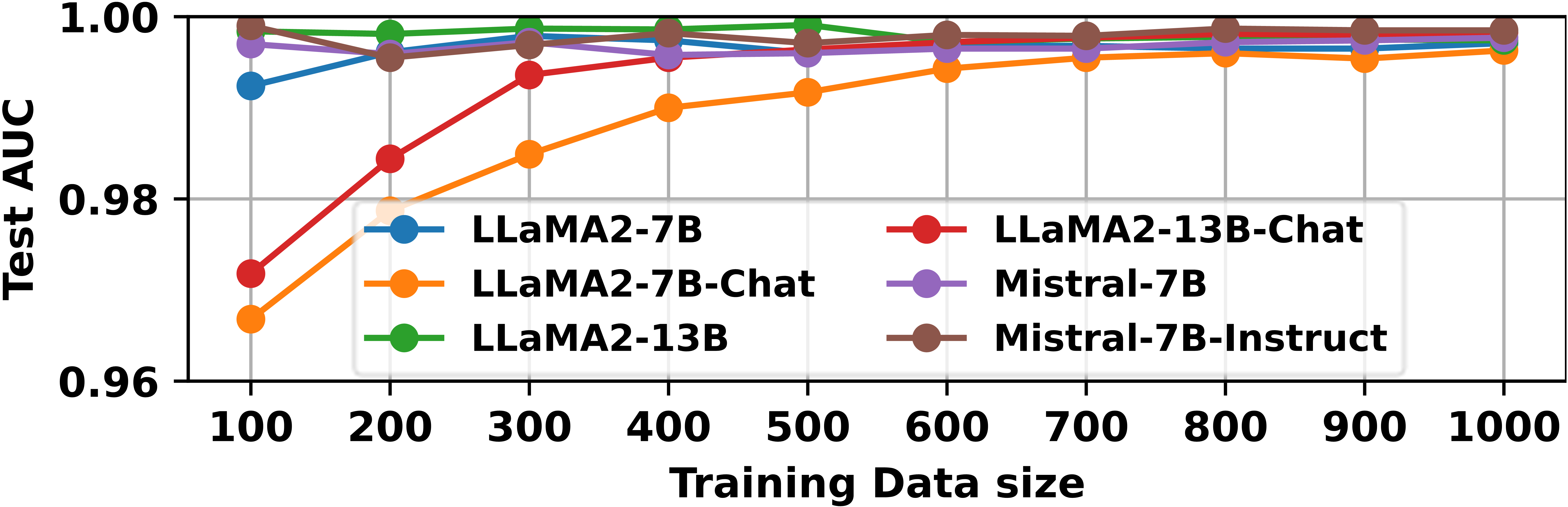
- Demonstrates robust generalization across different model families (Llama-2, Llama-3, Mistral) and sizes (7B, 13B).
Breakthrough Assessment
7/10
Strong empirical results and a lightweight, interpretable single-pass solution to a critical RAG problem. It smartly leverages internal attention signals rather than just output logits.