📝 Paper Summary
Model Compression
Post-training Sparsity
FCPTS enables fast, accurate post-training sparsity by learning optimal per-layer pruning thresholds via a differentiable bridge function based on kernel density estimation.
Core Problem
Existing post-training sparsity methods struggle with high sparsity rates because naive allocation ignores layer sensitivity, while retraining-based allocation is too slow and data-hungry for the post-training setting.
Why it matters:
- Deploying deep networks on edge devices requires reducing memory and energy use without extensive retraining costs
- Current post-training methods (like POT) crash in accuracy when sparsity exceeds 50%, limiting their practical utility
- Manual hyperparameter tuning for sparsity allocation is inefficient and cannot guarantee optimal global constraints
Concrete Example:
A naive post-training method might prune 80% of weights uniformly across all layers. If the first layer is highly sensitive, accuracy crashes. FCPTS automatically learns to prune the sensitive first layer less (e.g., 40%) and robust later layers more (e.g., 90%) to meet the global 80% target.
Key Novelty
Differentiable Bridge for Sparsity Allocation (FCPTS)
- Establishes a mathematical bridge between the non-differentiable sparsity rate and the pruning threshold using Kernel Density Estimation (KDE)
- Allows gradients to flow from the sparsity objective back to the pruning thresholds, enabling direct optimization of layer-wise sparsity rates via standard backpropagation
- Optimizes sparsity allocation and weight reconstruction jointly in a net-wise manner rather than layer-by-layer, satisfying global sparsity constraints exactly
Architecture
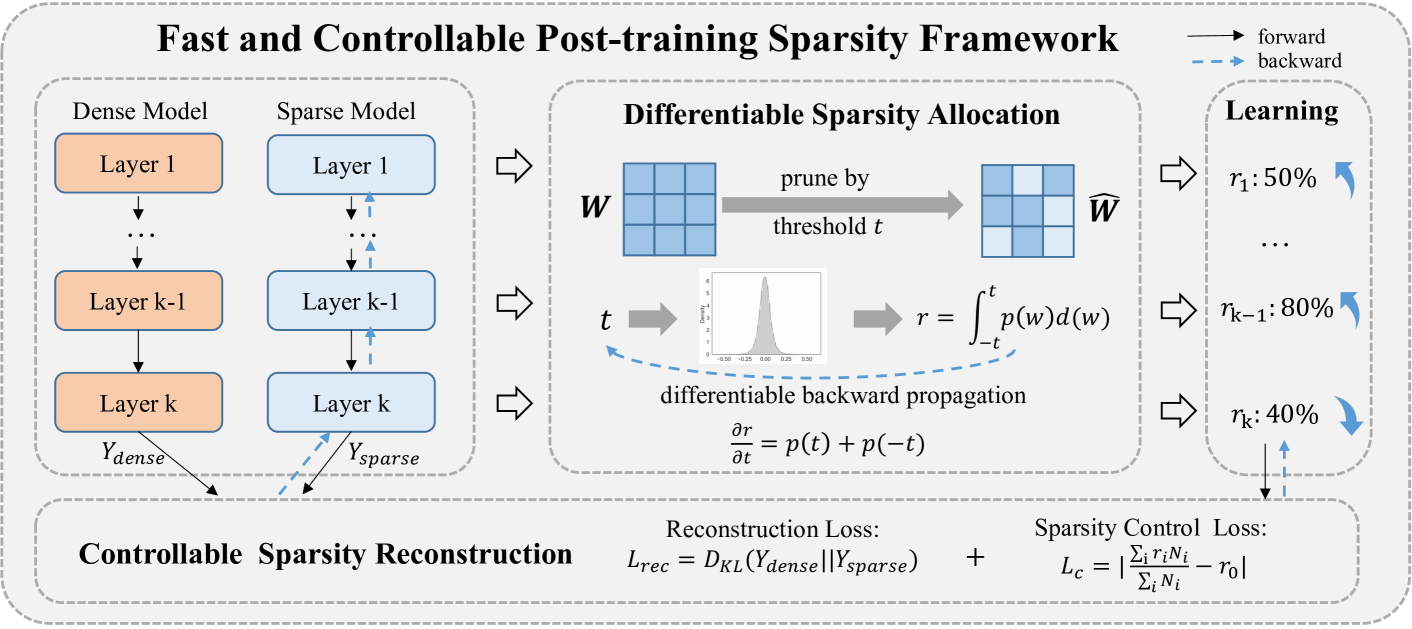
The FCPTS framework pipeline illustrating the flow from dense weights to sparse weights via the differentiable bridge.
Evaluation Highlights
- Over 30% accuracy improvement for ResNet-50 on ImageNet compared to state-of-the-art methods at 80% sparsity
- Achieves 70% global sparsity on ResNet-18 with accuracy on par with the dense counterpart (Top-1 Acc 69.76% vs 69.76%)
- Reduces processing time to minutes (e.g., ~30 mins for ResNet-18) compared to hours or days for retraining-based methods
Breakthrough Assessment
8/10
Significantly advances post-training sparsity by making the allocation process differentiable and fast. The large accuracy gains at high sparsity levels (80%) solve a major bottleneck in the field.