📝 Paper Summary
Model Compression
Hardware Acceleration
Computer Vision
Trio-ViT is a co-designed quantization and hardware acceleration framework specifically tailored for EfficientViT, exploiting its Softmax-free linear attention to achieve high-speed, low-precision inference on FPGAs.
Core Problem
Standard Vision Transformers are hard to quantize and accelerate due to non-linear operations like Softmax and GELU; existing solutions focus on standard ViTs and overlook the unique challenges (extreme activation variations) and opportunities (linear attention) of 'Efficient' ViTs.
Why it matters:
- Vision Transformers (ViTs) are computationally intensive, hindering deployment on edge devices with limited power and memory.
- Existing quantization methods for standard ViTs do not address the specific activation distributions found in Softmax-free EfficientViTs, leading to significant accuracy drops.
- Standard accelerators are optimized for quadratic attention and do not leverage the linear complexity or hybrid Convolution-Transformer structure of EfficientViTs.
Concrete Example:
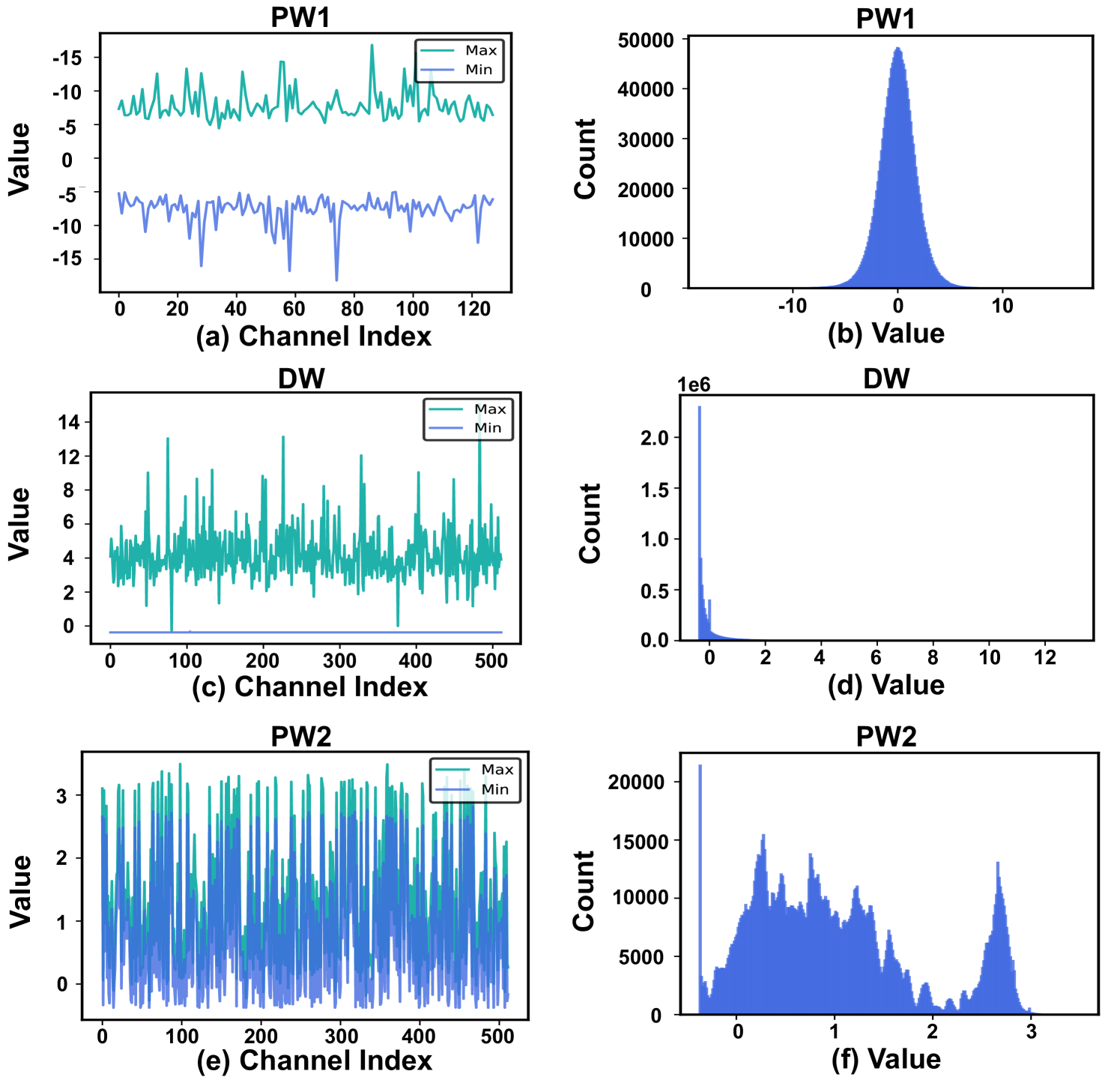
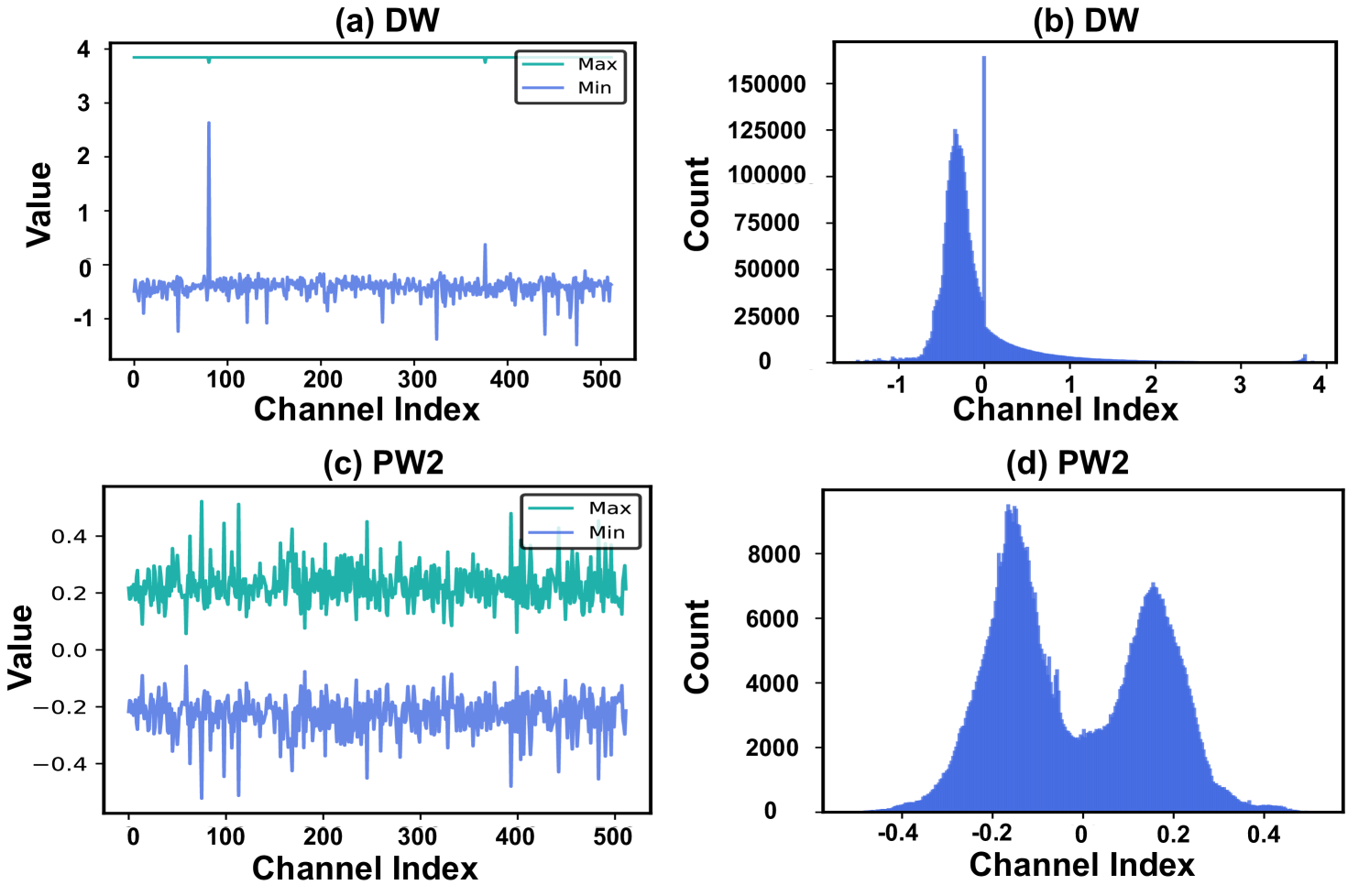
Quantizing activations in EfficientViT-B1 to 8-bit using standard methods causes a catastrophic accuracy drop of 76.15% due to extreme inter-channel variations in Depthwise Convolution inputs and value ranges in linear attention divisors.
Key Novelty
Algorithm-Hardware Co-design for Softmax-free EfficientViTs
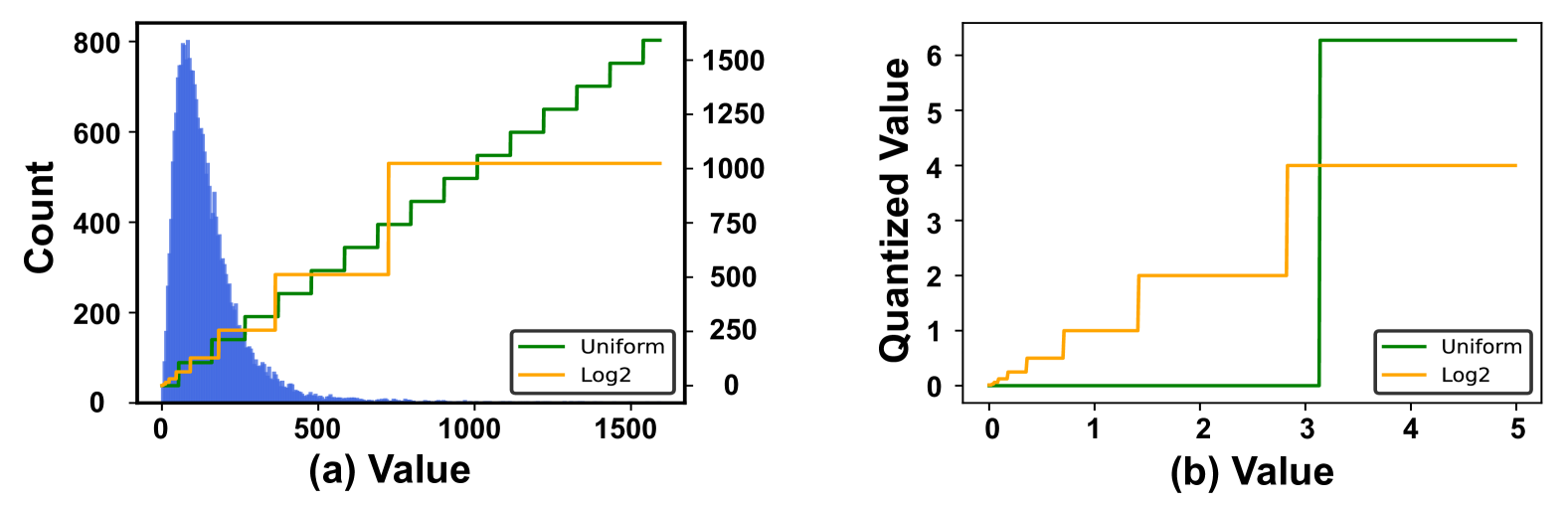
- Algorithm: Introduces 'channel-wise migration' to handle extreme variations in depthwise convolutions and 'log2 quantization' for sensitive divisors in linear attention, enabling accurate low-bit integer inference.
- Hardware: A hybrid accelerator architecture with specialized cores for both convolution and linear attention operations, featuring a pipeline designed to fuse layers and maximize utilization.
Architecture
Overview of the Trio-ViT hardware accelerator architecture.
Evaluation Highlights
- Achieves up to 7.3x FPS improvement over SOTA ViT accelerators (ViTCoD) with comparable accuracy on ImageNet.
- Delivers up to 6.0x higher DSP efficiency compared to existing FPGA-based ViT acceleration frameworks.
- Restores EfficientViT-B1 accuracy to within 0.36% of floating-point baseline using W8A8 quantization, recovering from a 76% drop with standard methods.
Breakthrough Assessment
7/10
Strong practical contribution for deploying efficient ViTs on edge hardware. effectively identifies and solves unique quantization hurdles in Softmax-free models that standard methods miss.