📝 Paper Summary
Post-Training Quantization (PTQ)
Large Language Model (LLM) Compression
aespa is a post-training quantization method that achieves accuracy comparable to block-wise optimization but at 10x speed by optimizing attention-output reconstruction through efficient pre-computed Hessians.
Core Problem
Existing Post-Training Quantization (PTQ) methods face a dilemma: layer-wise methods (like AdaRound) are fast but inaccurate for LLMs because they ignore cross-layer dependencies, while block-wise methods (like BRECQ) are accurate but computationally prohibitive for billion-parameter models.
Why it matters:
- Deploying hyper-scale models (LLMs) on edge devices requires aggressive compression (quantization) to reduce memory and compute costs
- Standard block-wise optimization (BRECQ) takes ~20 GPU hours for a small 2.7B model, making it impractical for frequent updates or larger models
- Existing fast methods (RTN, GPTQ) often fail at low bit-widths (e.g., INT2) or require unstable training processes
Concrete Example:
When quantizing the 6.7B parameter OPT model to INT2, standard methods like OmniQuant result in perplexity > 1000 (collapse), while block-wise methods like BRECQ run out of memory on a single A100 GPU.
Key Novelty
Attention-centric Efficient and Scalable Post-training Quantization Algorithm (aespa)
- Quantizes layers individually (for speed) but optimizes them to minimize the reconstruction error of the *entire attention module output* (for accuracy), capturing cross-layer dependencies
- Derives a refined objective function that allows the heavy computation (Hessians involving Attention matrices) to be pre-computed once using calibration data
- Optimizes Query, Key, and Value projections separately using upper-bound surrogates for the attention error, avoiding repeated softmax calculations during optimization
Architecture
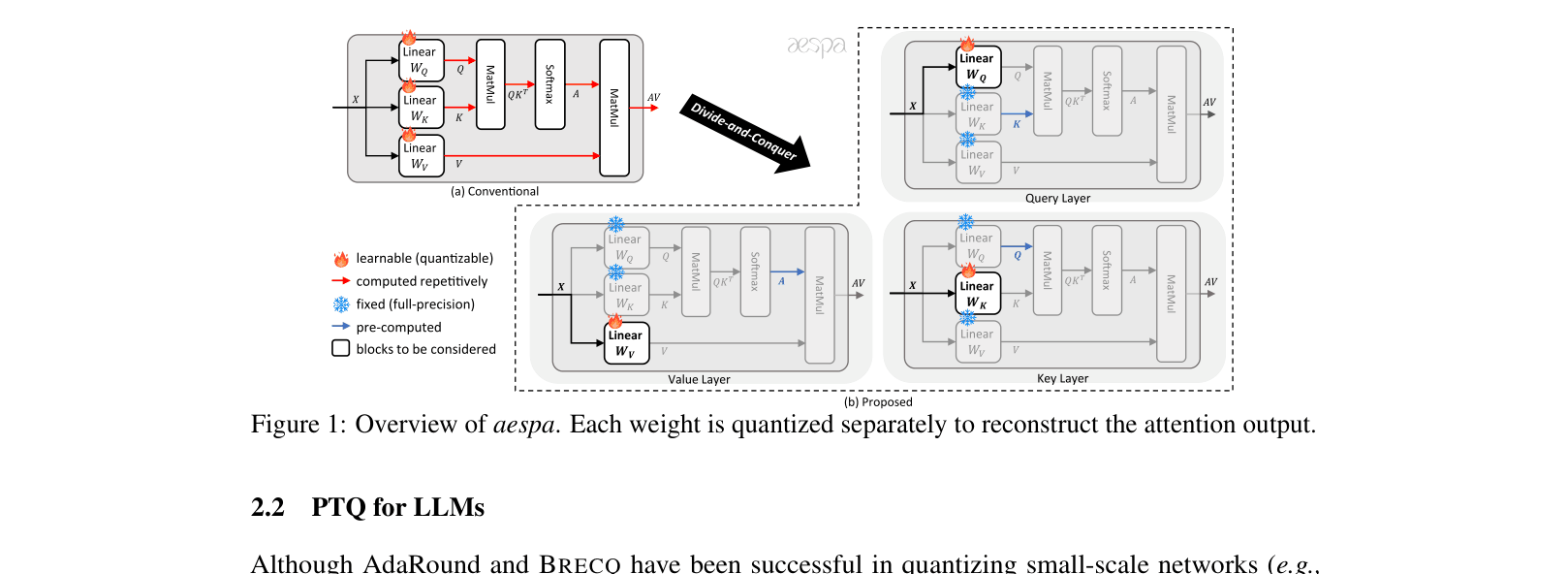
Overview of aespa's quantization strategy compared to existing methods (Layer-wise vs Block-wise)
Evaluation Highlights
- Achieves INT2 quantization on LLaMA-7B with 11.94 perplexity, significantly outperforming OmniQuant (18.18) and AffineQuant (18.83)
- Reduces quantization time for OPT-1.3B to 1.24 hours, compared to >10 hours for the baseline BRECQ method (approx. 10x speedup)
- Uniformly outperforms RTN, OPTQ, and Z-FOLD across OPT, BLOOM, and LLaMA families in INT2 precision settings
Breakthrough Assessment
8/10
Successfully bridges the gap between fast layer-wise and accurate block-wise quantization. The mathematical derivation allowing pre-computation makes advanced optimization feasible for very large models.