📝 Paper Summary
Model Compression
Post-Training Quantization (PTQ)
Large Language Models (LLMs)
BoA is a post-training quantization algorithm that optimizes weights by minimizing the attention reconstruction error rather than just layer-wise error, using a relaxed Hessian approximation to avoid backpropagation.
Core Problem
Existing quantization methods for LLMs either rely on slow backpropagation (impractical for billions of parameters) or assume layer independence (like GPTQ), which neglects how errors propagate through the attention mechanism.
Why it matters:
- Neglecting inter-layer dependencies, specifically within the attention module, leads to significant performance degradation in quantized Transformers.
- Gradient-based optimization methods (e.g., AdaRound) are too computationally expensive for hyper-scale LLMs.
- Computing the exact Hessian for attention layers involves a massive Jacobian of the softmax function, requiring prohibitive memory (e.g., >400GB for a small 125M model).
Concrete Example:
When quantizing the Query projection matrix, GPTQ minimizes the error of the projection output itself. However, this ignores that the output subsequently passes through a Softmax function and multiplies with the Value matrix. A small error in the projection might be amplified or suppressed by the Softmax/Value interaction, which GPTQ fails to capture.
Key Novelty
Attention-aware Relaxed Hessian Optimization
- Approximates the Hessian using the 'attention reconstruction error' (output of the entire attention block) instead of layer-wise error, capturing dependencies between Query, Key, and Value layers.
- Introduces a 'Relaxed Hessian' that uses a surrogate upper bound for the error, eliminating the need to compute the memory-intensive Jacobian of the softmax function.
- Utilizes properties of the Kronecker product to invert the larger, dependency-aware Hessian matrices efficiently without increasing computational complexity order.
Architecture
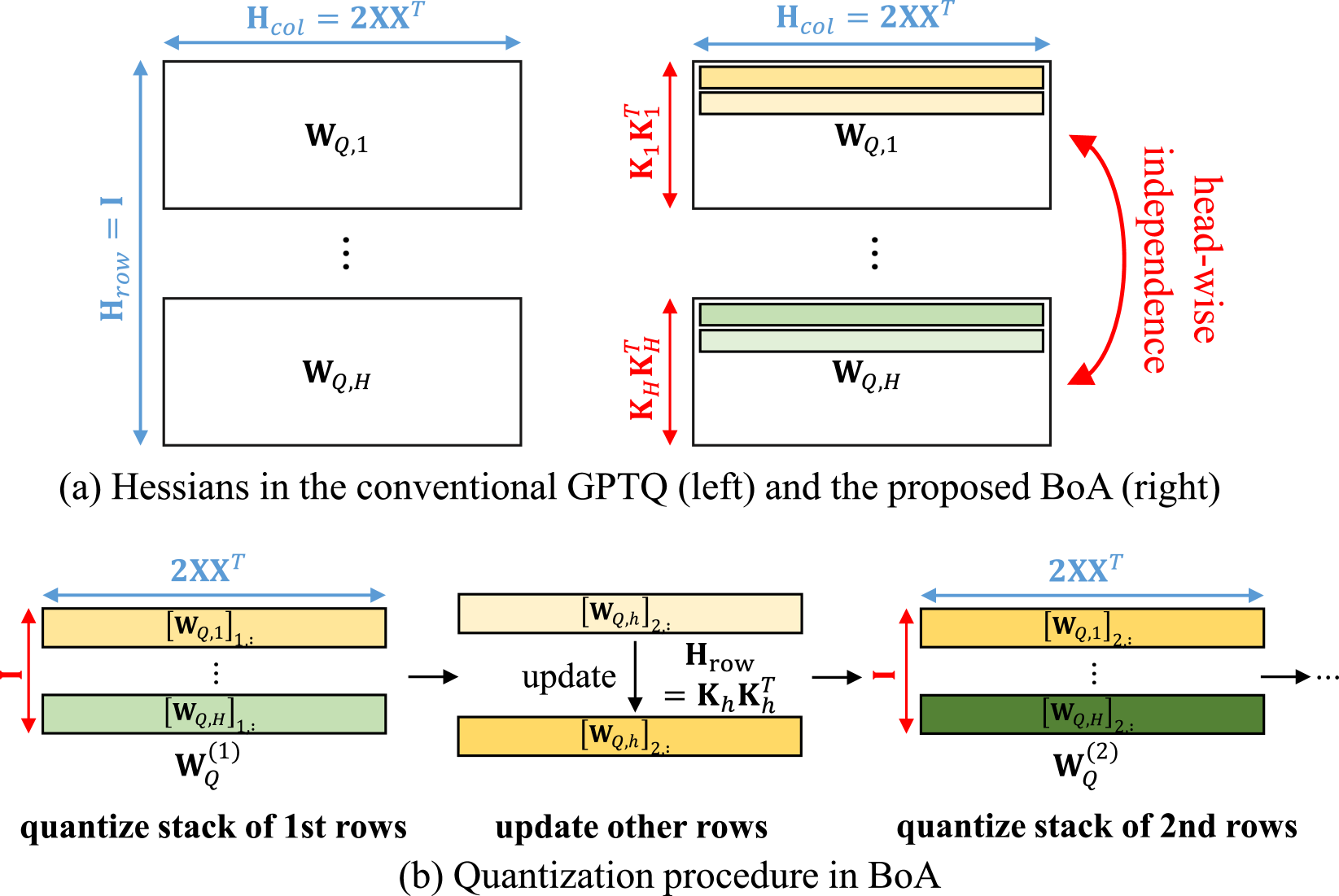
Conceptual illustration of the Head-wise Simultaneous Quantization strategy.
Evaluation Highlights
- Achieves >40x reduction in processing time on a 30B model by utilizing head-wise simultaneous quantization compared to sequential row updates.
- Claims to outperform existing backpropagation-free methods (like GPTQ) by a significant margin, particularly in low-bit precision settings (e.g., INT2) (Qualitative claim; exact accuracy numbers not in provided text).
- Claims state-of-the-art performance for weight-activation quantization when combined with outlier suppression methods like QuaRot (Qualitative claim).
Breakthrough Assessment
7/10
Significant methodological improvement by incorporating inter-layer dependencies into a backprop-free framework. Effectively bridges the gap between fast layer-wise methods (GPTQ) and slow block-wise methods (BRECQ).