📝 Paper Summary
Model Compression
Diffusion Transformers (DiTs)
Post-Training Quantization (PTQ)
VQ4DiT enables extremely low bit-width compression of Diffusion Transformers by simultaneously calibrating both the codebook and vector assignments using a zero-data, block-wise strategy, avoiding gradient inconsistencies.
Core Problem
Traditional Vector Quantization (VQ) methods only calibrate the codebook without adjusting assignments, causing weight sub-vectors to be incorrectly mapped and providing inconsistent gradients that degrade performance at low bit-widths.
Why it matters:
- Diffusion Transformers (DiTs) like DiT-XL/2 are computationally expensive (17+ seconds/image on A100) and memory-intensive, hindering edge deployment.
- Standard uniform quantization fails at extremely low bit-widths (e.g., 2-bit), causing severe quality degradation.
- Existing VQ methods for CNNs rely on time-consuming fine-tuning on full datasets, which is impractical for large generative models.
Concrete Example:
When quantizing a DiT model to 2-bit, standard methods result in poor image quality (FID > 48) because sub-vectors with the same assignment may have gradients pointing in different directions, preventing the codebook from converging to an optimal state.
Key Novelty
Simultaneous Codebook and Assignment Calibration
- Instead of fixing assignments after K-Means clustering, the method treats assignments as learnable probability distributions (soft assignments) over a candidate set.
- A zero-data calibration strategy uses synthetic Gaussian noise inputs to generate outputs, minimizing the error between floating-point and quantized block outputs to tune both codebooks and assignment ratios simultaneously.
Architecture
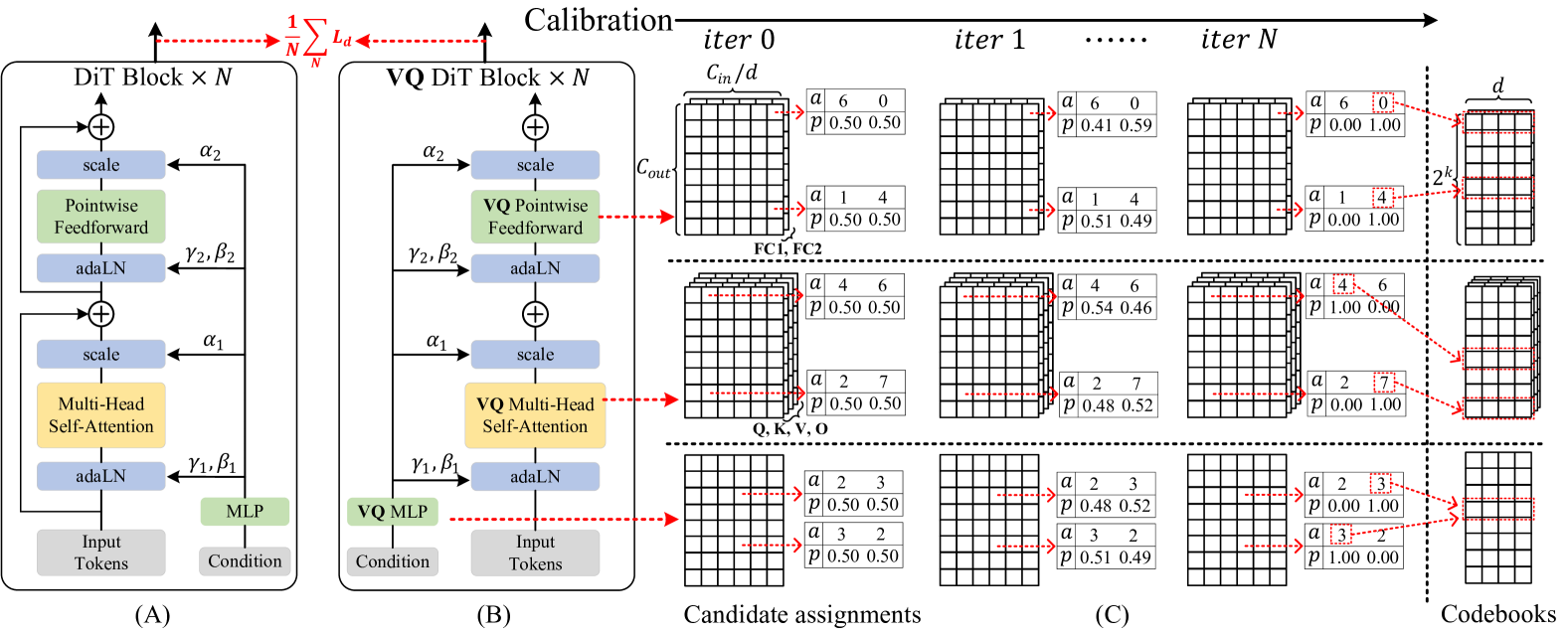
Overview of the VQ4DiT framework, contrasting it with the standard DiT block structure.
Evaluation Highlights
- Achieves 3.32 FID on ImageNet 256x256 with 2-bit weights, effectively matching the full-precision model (2.27 FID) while using significantly less memory.
- Outperforms standard uniform quantization (UQ) significantly; at 2-bit, UQ fails completely (FID 260.07) while VQ4DiT maintains high generation quality.
- Quantizes a DiT XL/2 model on a single NVIDIA A100 GPU within 20 minutes to 5 hours depending on settings, without requiring real training data.
Breakthrough Assessment
8/10
First successful application of Vector Quantization to Diffusion Transformers at extremely low bit-widths (2-bit) with a novel simultaneous calibration mechanism, addressing a key limitation of prior VQ methods.