📝 Paper Summary
Model Compression
Post-Training Quantization (PTQ)
DopQ-ViT improves low-bit vision transformer quantization by using a tangent-based function to preserve extreme activation values and a statistical method to identify optimal scaling factors for outlier channels.
Core Problem
Post-training quantization for Vision Transformers degrades significantly at low bit-widths (e.g., 3-bit) due to imbalanced activation distributions and outliers.
Why it matters:
- Vision Transformers have high computational costs, limiting deployment on edge devices with constrained memory and power.
- Existing quantizers focus on values near 0 but neglect crucial values near 1 in Softmax outputs, destroying model information.
- Standard reparameterization techniques for LayerNorm fail because they use mean scaling factors that are skewed by abnormal outlier channels.
Concrete Example:
In a ViT-B model, removing just the top 1% of activation values near 1 causes accuracy to drop to 2.20%, yet standard Log2 quantizers allocate almost no precision to this region. Similarly, using a simple mean for scaling factors drops accuracy by ~15% compared to channel-wise quantization.
Key Novelty
DopQ-ViT (Distribution-friendly and Outlier-aware Post-training Quantization)
- Introduces Tan Quantizer (TanQ), which uses a tangent function to map quantization intervals. This allocates high precision to both the dense values near 0 and the sparse but critical values near 1.
- Proposes MAD-guided Optimal Scaling Factor (MOSF), a search-free method that uses Mean Absolute Deviation to select a scaling factor robust to outliers in LayerNorm activations.
Architecture
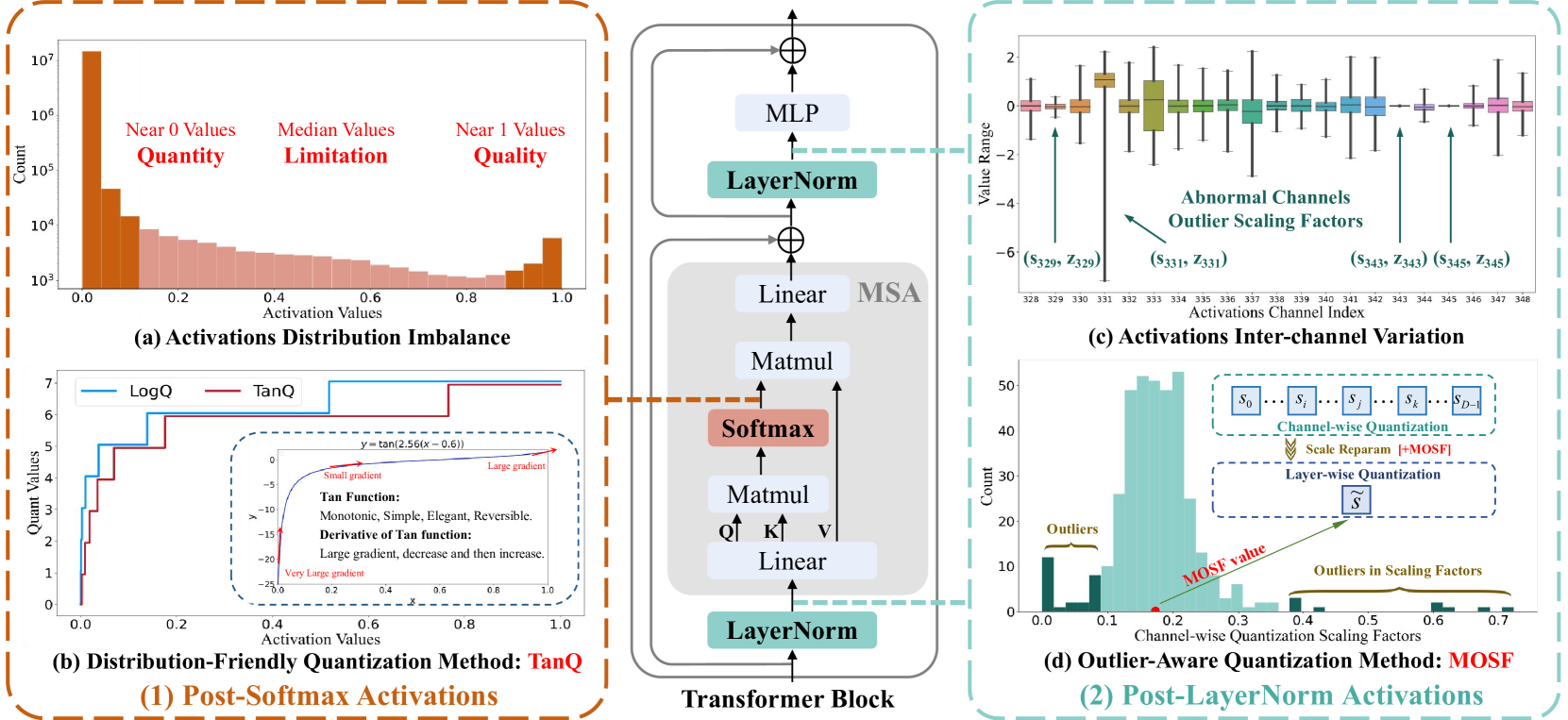
Comparison of activation distributions and quantization functions. (a) Histogram of post-Softmax activations. (b) Curves for Log2, Uniform, and Tan Quantizers. (c) Channel-wise variations in post-LayerNorm activations.
Evaluation Highlights
- Outperforms state-of-the-art PTQ methods (like RepQ-ViT and I&S-ViT) on ImageNet classification and COCO detection tasks.
- Achieves significant accuracy recovery under aggressive low-bit settings (e.g., W3A3), where prior methods suffer major degradation.
- MOSF prevents the ~15% accuracy drop observed when transitioning from channel-wise to layer-wise quantization in ViT-S models.
Breakthrough Assessment
7/10
Solid incremental improvement for low-bit ViT quantization. Identifies specific failure modes of previous log-quantizers (ignoring values near 1) and provides a mathematically grounded, efficient fix.