📝 Paper Summary
Structured Pruning
Dynamic Inference
Parameter Efficiency
IFPruning is a dynamic structured pruning method that uses a lightweight predictor to select and activate task-specific parameters based on user instructions, enabling a single model to adapt its active sub-network for different tasks.
Core Problem
Static structured pruning creates a fixed, smaller model that may struggle to balance performance across diverse tasks (e.g., coding vs. math), as different tasks require distinct skills and parameters.
Why it matters:
- Static pruning permanently removes parameters, potentially degrading performance on specific domains that relied on the pruned weights
- Existing dynamic methods like Mixture-of-Experts or contextual sparsity often incur high weight-loading costs at every decoding step
- On-device deployment requires reducing inference costs while maintaining the versatility of large models across varying user queries
Concrete Example:
A static pruned model might retain general language parameters but lose specialized coding weights. When asked to write Python code, it fails because the necessary parameters were permanently removed. IFPruning dynamically activates coding-specific weights for that prompt while keeping the total active parameter count low.
Key Novelty
Instruction-Following Pruning (IFPruning)
- Introduces a 'sparsity predictor' that takes the user prompt as input and predicts a binary mask for Feed-Forward Network (FFN) layers before decoding begins
- Uses 'SoftTopK' to make the mask generation differentiable, allowing joint optimization of the predictor and the LLM backbone during training
- Selects parameters per-input or per-task and caches them, avoiding the per-token weight loading overhead found in traditional Mixture-of-Experts or contextual sparsity methods
Architecture
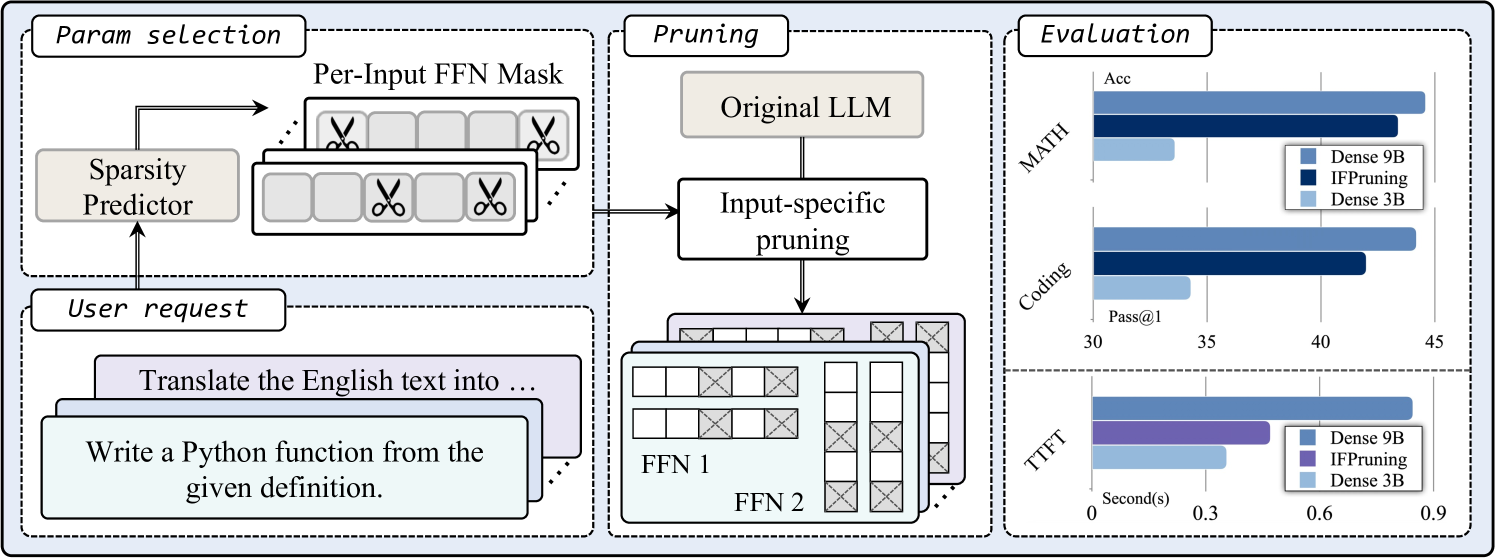
The IFPruning inference pipeline. A user prompt is processed by a sparsity predictor to generate masks, which are then applied to the FFN layers of the main LLM.
Evaluation Highlights
- IFPruning (activating 3B parameters from 9B) outperforms a standard 3B dense model by 8% on coding tasks and 5% on math benchmarks
- Reduces time-to-first-token by up to 57% and generation time by up to 41% compared to the full model
- Rivals the performance of the unpruned 9B source model on domains like math and coding while using only 3B parameters
Breakthrough Assessment
7/10
Strong conceptual shift from static to instruction-driven dynamic pruning with practical latency benefits. While similar to MoE routing, the 'per-prompt' rather than 'per-token' selection is a valuable engineering trade-off for on-device inference.