📝 Paper Summary
Post-Training Quantization (PTQ)
Model Compression
Transformer Quantization
RepQuant decouples quantization from inference by employing complex, distribution-aware quantizers during calibration and converting them into efficient, hardware-friendly quantizers for inference via mathematically equivalent scale reparameterization.
Core Problem
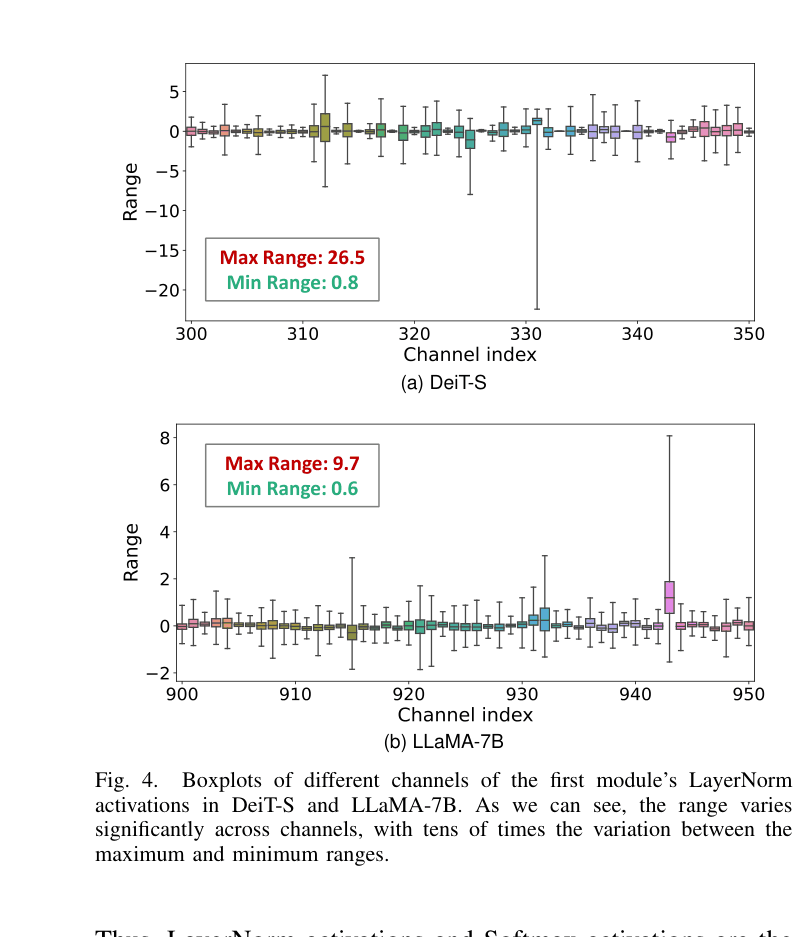
Large transformer models exhibit extreme activation distributions (severe inter-channel variations in LayerNorm, power-law characteristics in Softmax) that cause significant accuracy loss when quantized with simple hardware-friendly quantizers.
Why it matters:
- Existing Post-Training Quantization (PTQ) methods over-prioritize hardware compatibility during the calibration phase, leading to poor representation of outliers
- Low-bit quantization (e.g., 4-bit) of large transformers typically fails or degrades performance catastrophically without retraining
- Large models (ViT, LLaMA) are computationally expensive; efficient inference on standard hardware requires simplified quantization schemes (layer-wise, log2) which normally sacrifice accuracy
Concrete Example:
In DeiT-S, LayerNorm activation ranges vary by 33x across channels (0.8 vs 26.5). Forcing a single layer-wise quantization scale (hardware-friendly) lumps these distinct distributions together, causing massive error. RepQuant uses channel-wise quantization first to capture this, then mathematically folds the scales into weights to allow layer-wise inference.
Key Novelty
Quantization-Inference Decoupling via Scale Reparameterization
- Use complex quantizers (channel-wise for LayerNorm, Log-sqrt2 for Softmax) during the calibration phase to accurately capture extreme distributions.
- Transform these complex quantizers into simplified ones (layer-wise, Log2) for the inference phase through mathematically equivalent reparameterization of weights and biases.
- Introduce learnable per-channel dual clipping to identify fine-grained upper and lower bounds for outliers, minimizing quantization error in the integer space.
Architecture
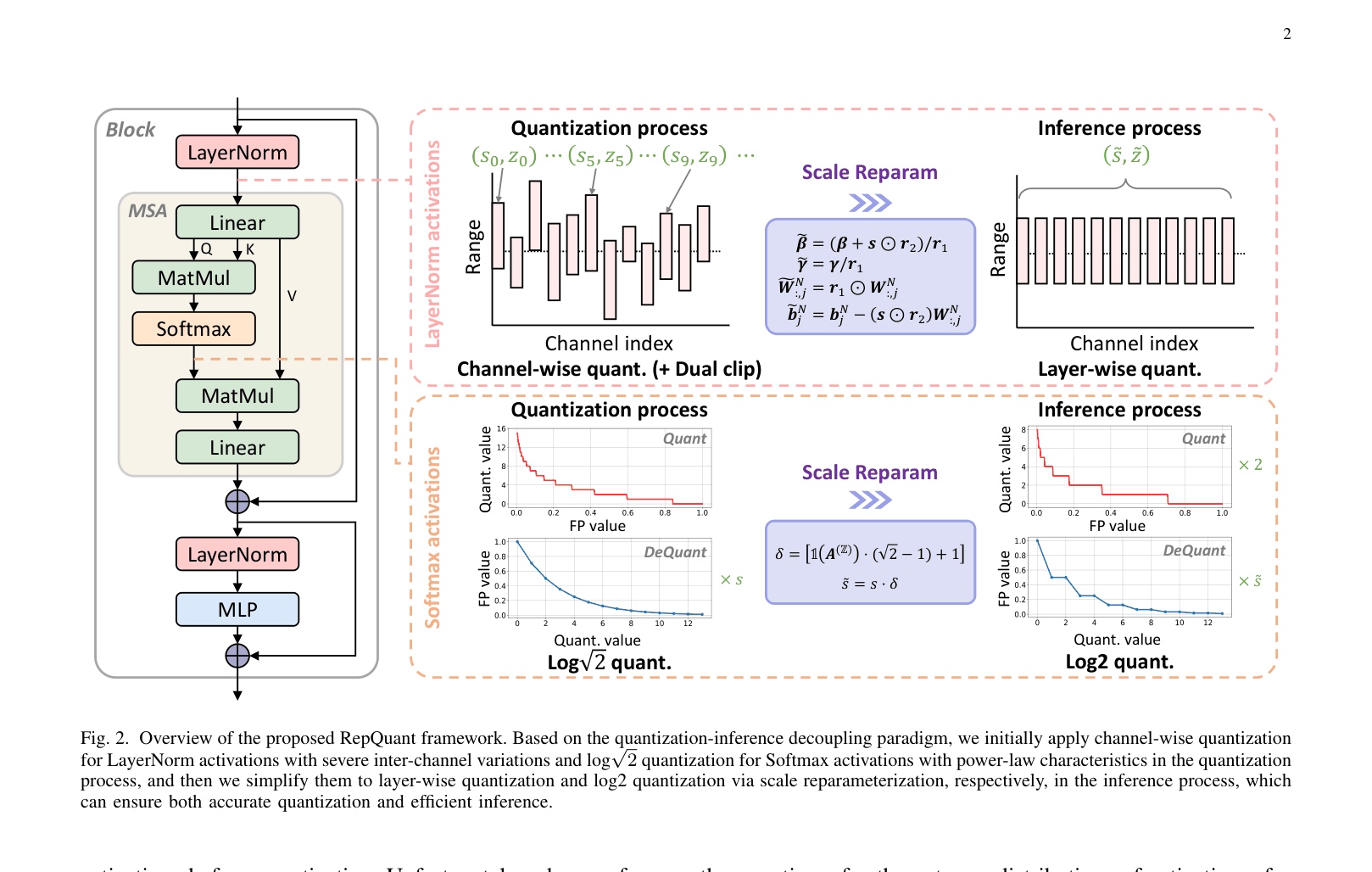
Overview of the RepQuant framework, contrasting the Quantization Process with the Inference Process.
Evaluation Highlights
- +30.7% accuracy gain on ImageNet (ViT-S, W4/A4) compared to PTQ4ViT baseline (73.28% vs 42.57%).
- +30.3 mAP improvement on COCO Object Detection (Mask R-CNN with Swin-T, W4/A4) compared to PTQ4ViT (37.2 vs 6.9).
- Achieves <1% accuracy drop compared to full-precision models for most Vision Transformers in W6/A6 settings.
Breakthrough Assessment
8/10
Significantly outperforms existing PTQ methods in low-bit settings by resolving the conflict between accurate outlier representation and efficient hardware inference.