📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Synthetic Data Generation
Curriculum Learning
eva casts RL post-training as an infinite game where a Creator agent adaptively evolves challenging prompts based on regret signals, enabling a Solver agent to continuously improve beyond static datasets.
Core Problem
Standard RL post-training relies on static, pre-curated prompt distributions, causing models to stop learning once they saturate performance on this fixed set.
Why it matters:
- Training Efficiency: Treating all prompts equally is inefficient, as not all prompts are informative for the model's current state
- Model Generalizability: Learning bottlenecks on the static distribution, preventing the acquisition of new skills or robustness needed for open-ended real-world scenarios
Concrete Example:
A model might master a static set of creative writing prompts (achieving low regret). In standard RLHF, training stagnates. With eva, the system detects this low regret and generates new, more complex constraints (e.g., 'write a poem without using the letter e'), forcing the model to learn new capabilities.
Key Novelty
Evolving Alignment via Asymmetric Self-Play (eva)
- Treats post-training as a two-player game: a Creator generates difficult prompts, and a Solver learns to answer them, converging towards a minimax regret equilibrium
- Uses 'informativeness' (estimated reward advantage) as a signal to identify which prompts are worth evolving, rather than evolving prompts uniformly or randomly
- Allows continuous self-improvement in both offline (batch) and online (streaming) RL settings by dynamically refreshing the training distribution
Architecture
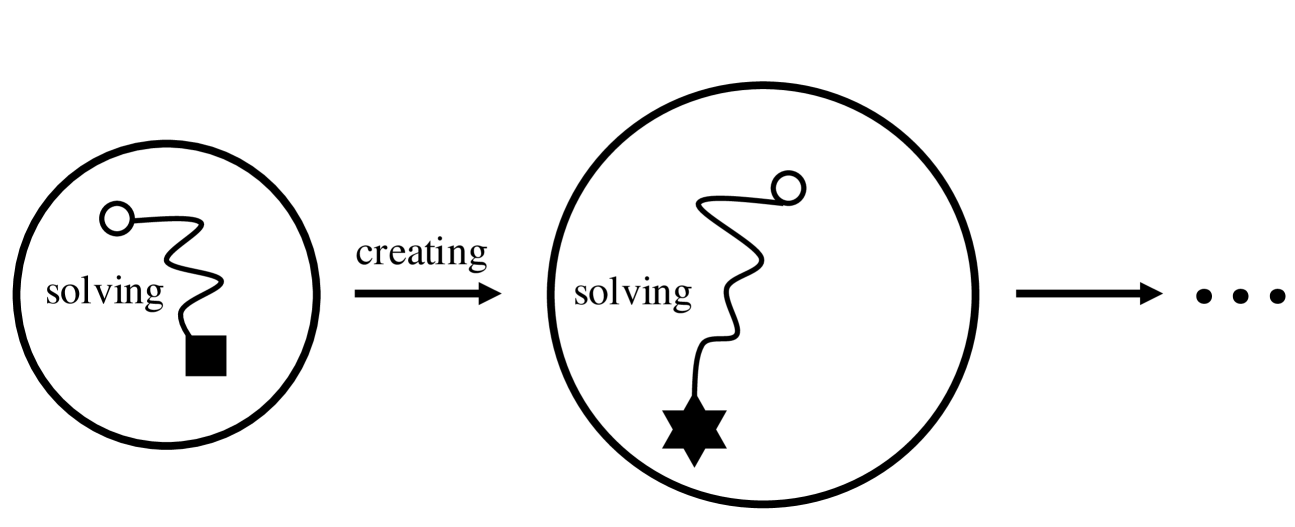
The asymmetric self-play game between the Creator and Solver. It illustrates the iterative process where the Creator updates the prompt distribution based on the Solver's regret.
Evaluation Highlights
- +8.5% win-rate increase on Arena-Hard for gemma-2-9b-it using DPO (51.6% -> 60.1%) without extra human prompts
- +9.8% win-rate increase on Arena-Hard for gemma-2-9b-it using RLOO (52.6% -> 62.4%), surpassing the proprietary Claude-3-Opus
- Demonstrates robustness across multiple RL algorithms (DPO, RLOO, SimPO, SPPO, ORPO), consistently improving performance over static baselines
Breakthrough Assessment
8/10
Significant performance jumps on high-quality benchmarks (Arena-Hard) using a self-play mechanism that removes the dependency on static prompt engineering. The method is agnostic to the underlying RL algorithm.