📝 Paper Summary
Model Quantization
Image Super-Resolution
Efficient Deep Learning
2DQuant is a two-stage post-training quantization method for super-resolution Transformers that initializes quantizer bounds based on distribution type and fine-tunes them via distillation to minimize accuracy loss at low bit-widths.
Core Problem
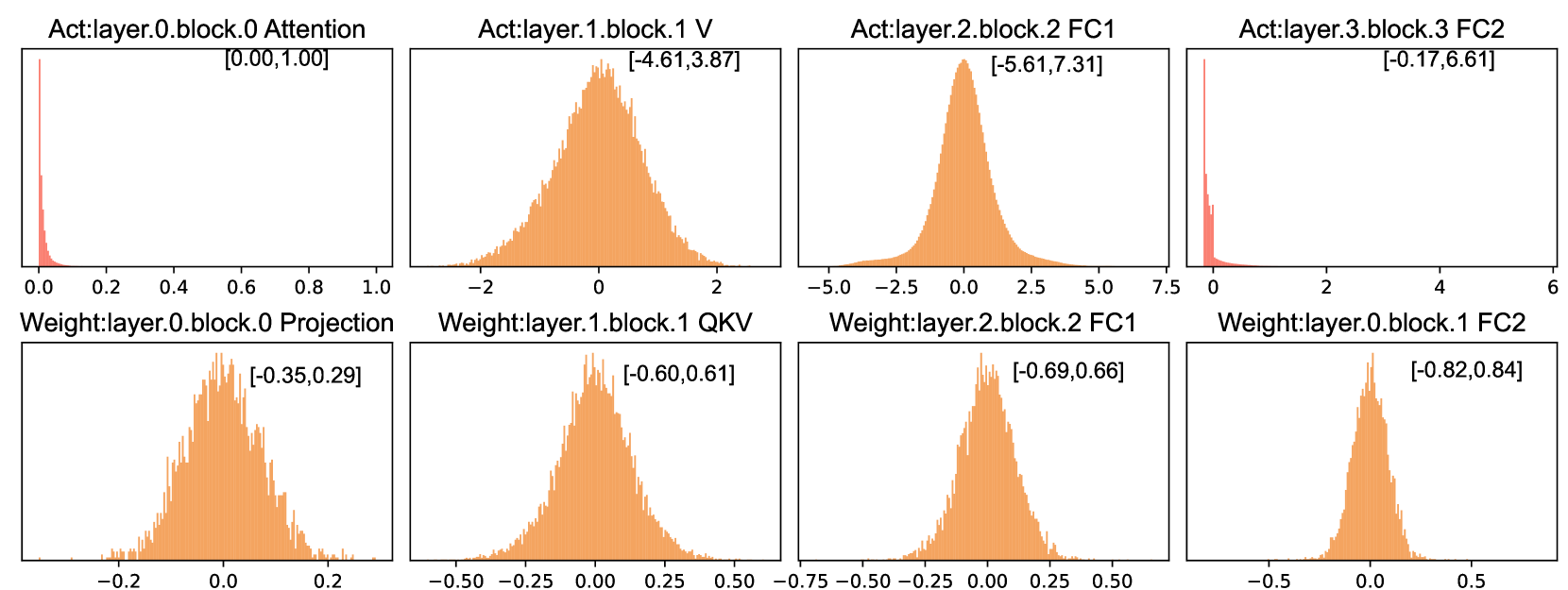
Post-training quantization (PTQ) for super-resolution (SR) suffers severe accuracy degradation at low bit-widths, especially for Transformer-based models which have distinct, asymmetric activation distributions compared to CNNs.
Why it matters:
- Advanced SR models (like Transformers) are computationally heavy, hindering deployment on edge devices with limited storage and compute.
- Existing PTQ methods are optimized for CNNs (like EDSR) and fail to handle the long-tail, asymmetric distributions found in Transformers (like SwinIR), leading to visual artifacts.
- Training-aware quantization (QAT) is resource-intensive; PTQ offers a faster alternative but currently lacks precision for advanced architectures.
Concrete Example:
When quantizing the SwinIR model to 4 bits using existing methods like DBDC+Pac, the output image suffers from severe distorted artifacts and color shifts compared to the original high-resolution image, whereas 2DQuant maintains visual fidelity.
Key Novelty
Two-stage Coarse-to-Fine Quantization (DOBI + DQC)
- Stage 1 (DOBI): Initializes quantization bounds by detecting distribution types (bell-shaped vs. exponential/long-tail) and applying specialized search strategies (symmetric vs. asymmetric) to minimize local error.
- Stage 2 (DQC): Fine-tunes these bounds using knowledge distillation, where the quantized model learns to match the full-precision model's output and intermediate features, correcting the global task-specific error.
Architecture
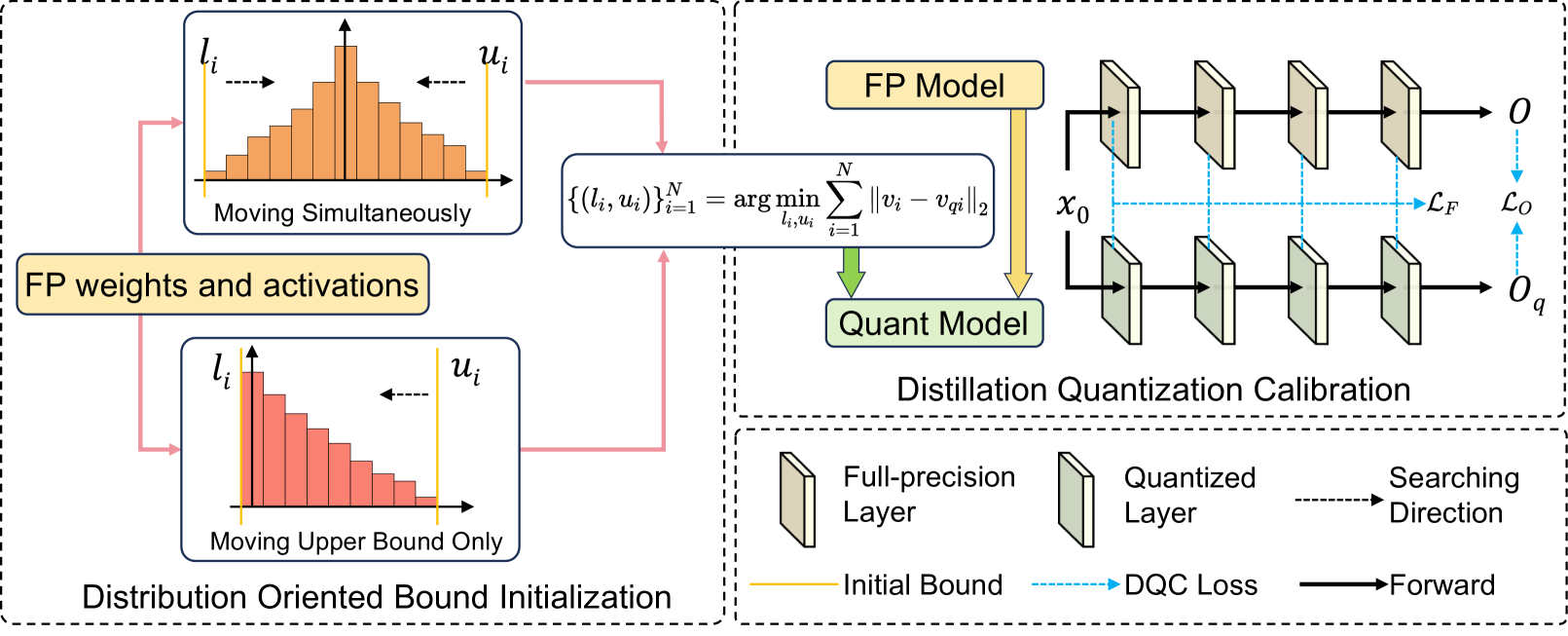
The overall pipeline of 2DQuant, illustrating the two-stage process.
Evaluation Highlights
- +4.52 dB PSNR improvement on Set5 (×2 scale) compared to SOTA (DBDC+Pac) when quantizing SwinIR to 2-bit.
- Achieves 3.60× compression ratio and 5.08× speedup ratio at 2-bit quantization with minimal performance loss compared to full precision.
- Surpasses existing PTQ methods on all five benchmarks (Set5, Set14, B100, Urban100, Manga109) at 2, 3, and 4 bits.
Breakthrough Assessment
8/10
Significantly advances PTQ for SR by effectively handling Transformers at extremely low bits (2-bit), a regime where previous methods failed catastrophically. The two-stage approach is logical and yields large metric gains.