📝 Paper Summary
Post-Training Quantization (PTQ)
Model Compression
COMQ is a backpropagation-free quantization algorithm that iteratively minimizes layer-wise reconstruction error by updating single weights or scaling factors in a greedy coordinate-descent manner.
Core Problem
Post-training quantization often suffers significant accuracy degradation, especially for Vision Transformers (ViTs), while existing methods either require computationally expensive backpropagation (like QAT) or rely on complex Hessian inversions.
Why it matters:
- Deploying large models (ViTs, LLMs) on resource-constrained devices requires reducing memory footprint via low-bit quantization without retraining.
- Existing PTQ methods struggle to balance high accuracy with computational efficiency, often failing to preserve performance in sensitive architectures like ViTs at low bit-widths (e.g., 4-bit).
- Backpropagation-based methods are slow and memory-intensive, while simpler rounding methods cause too much error.
Concrete Example:
Standard rounding (Nearest-Neighbor) for a 4-bit Vision Transformer might drop accuracy by over 50% because it ignores the interplay between weights. COMQ iteratively adjusts one weight at a time to compensate for errors introduced by quantizing others, recovering nearly full accuracy.
Key Novelty
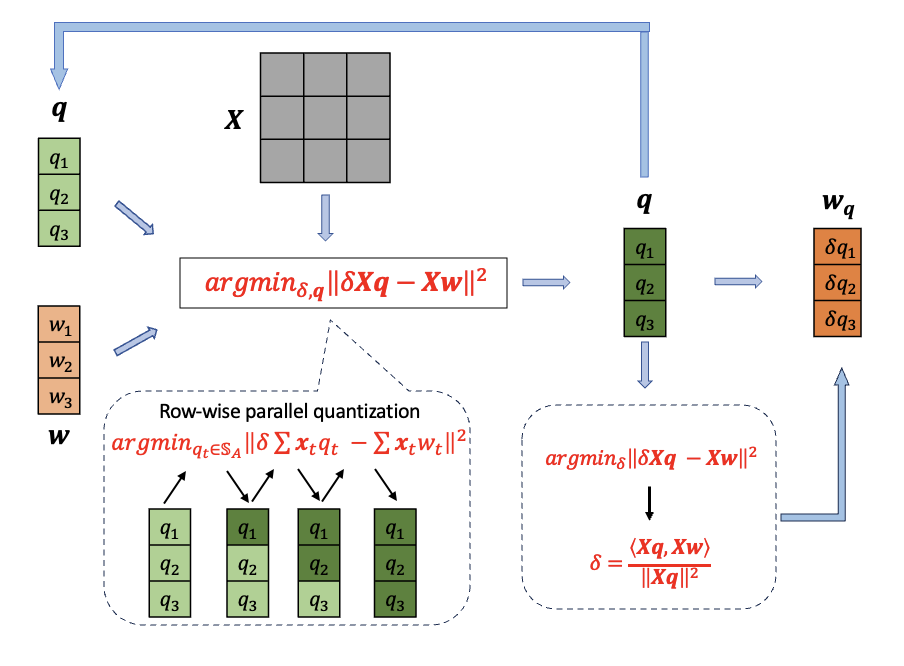
Coordinate Minimization for Quantization (COMQ)
- Reformulates quantization as a coordinate descent problem where every quantized weight (integer code) and scaling factor is a variable to be optimized.
- Updates one variable at a time (greedy selection) to minimize local reconstruction error while keeping others fixed, using a closed-form solution that requires only dot products and rounding.
- Does not use backpropagation or Hessian inverses, making it computationally lightweight and hyperparameter-free.
Architecture
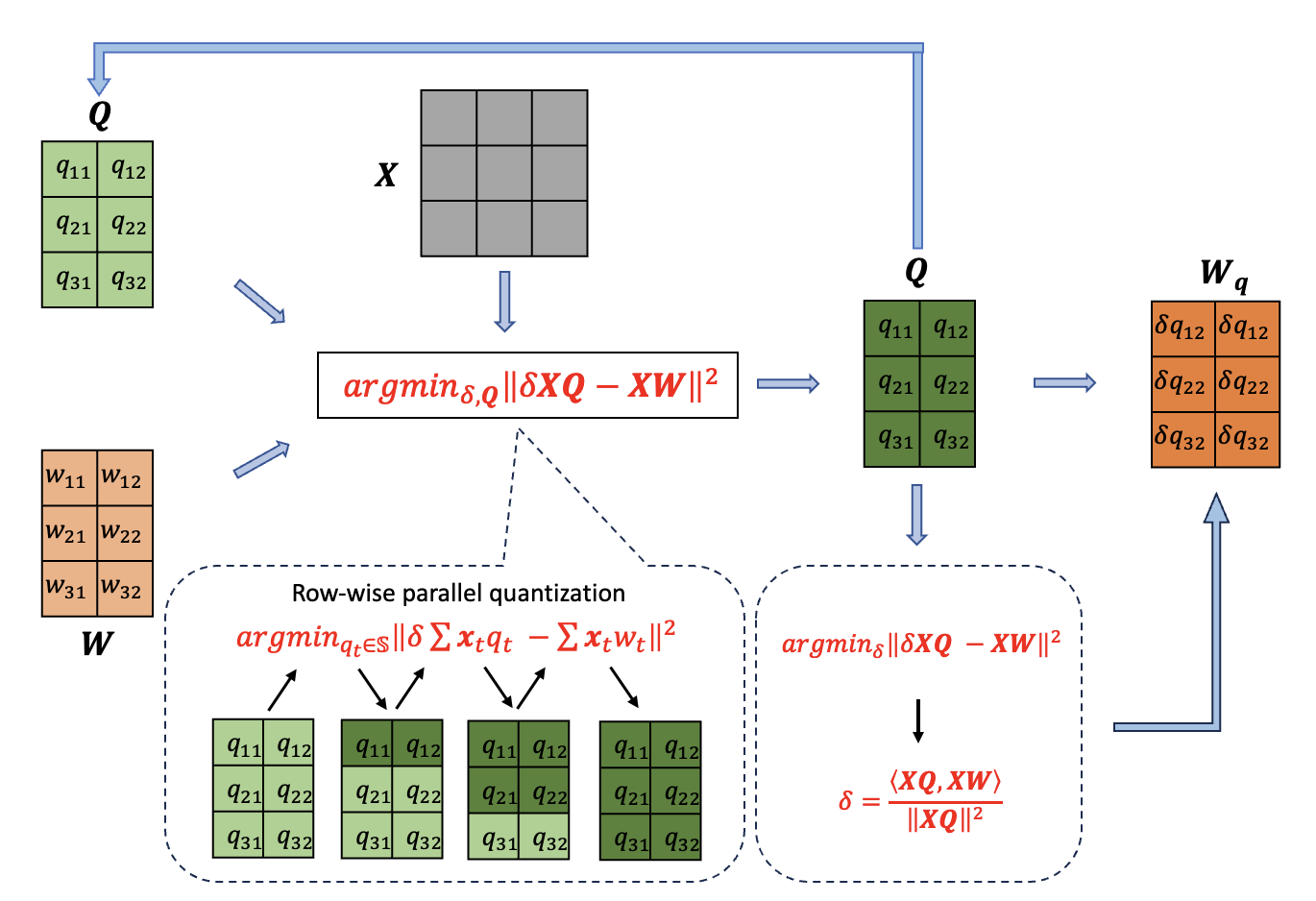
Illustration of the coordinate-wise update process. It shows a weight matrix W and input X. The algorithm selects one element of the quantized weight matrix Q (an integer bit-code) or the scaling factor delta to update while fixing all others.
Evaluation Highlights
- Achieves 4-bit quantization of Vision Transformers (DeiT-S, DeiT-B, ViT-B) with <1% Top-1 accuracy loss compared to full precision.
- Maintains near-lossless accuracy (0.05% drop) for 4-bit quantization of ResNet-18 and ResNet-50 on ImageNet.
- Outperforms state-of-the-art PTQ methods (like BRECQ, QDrop, PD-Quant) on ViTs with per-channel quantization.
Breakthrough Assessment
8/10
Offers a highly efficient, mathematically grounded alternative to backpropagation-based PTQ. It achieves SOTA results on difficult ViT architectures without the complexity of Hessian-based methods or the cost of QAT.