📝 Paper Summary
LLM Post-training
Synthetic Data Generation
Automated Evaluation
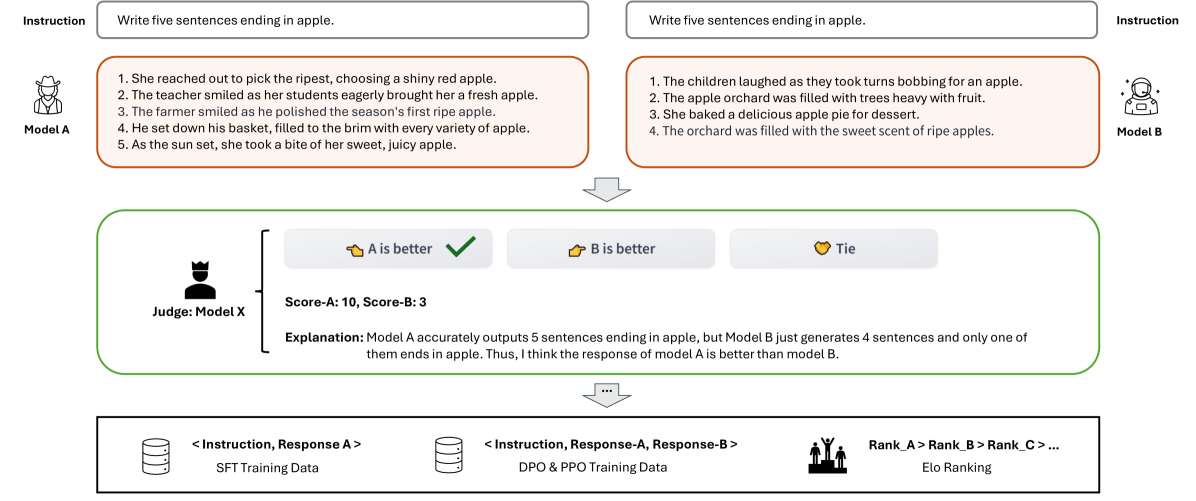
Arena Learning automates the post-training data pipeline by simulating offline chatbot battles with an AI judge to iteratively generate high-quality preference data for SFT, DPO, and PPO.
Core Problem
Human-annotated chatbot arenas are expensive, slow, and operationally limited, restricting the amount of high-quality preference data available for continuous model improvement.
Why it matters:
- Relying on human evaluation bottlenecks the 'data flywheel' needed to constantly update models with fresh feedback
- Most models cannot participate in public arenas due to priority limits, meaning researchers miss out on valuable comparative failure cases against state-of-the-art models
Concrete Example:
A target model might fail to answer a complex reasoning question that a stronger competitor (e.g., GPT-4) answers correctly. In a standard setup, the target model never sees this comparison. Arena Learning simulates this battle offline, identifies the failure, and uses the competitor's win to generate a training signal.
Key Novelty
Offline Simulated Arena & Iterative Data Flywheel
- Replaces human annotators with a strong 'judge model' (Llama-3-70B) to adjudicate battles between the target model and diverse SOTA competitors offline
- Creates a closed-loop 'flywheel' where battle outcomes (wins/losses) are immediately converted into training data for SFT (learning from winners), DPO, and PPO to upgrade the model for the next round
Architecture
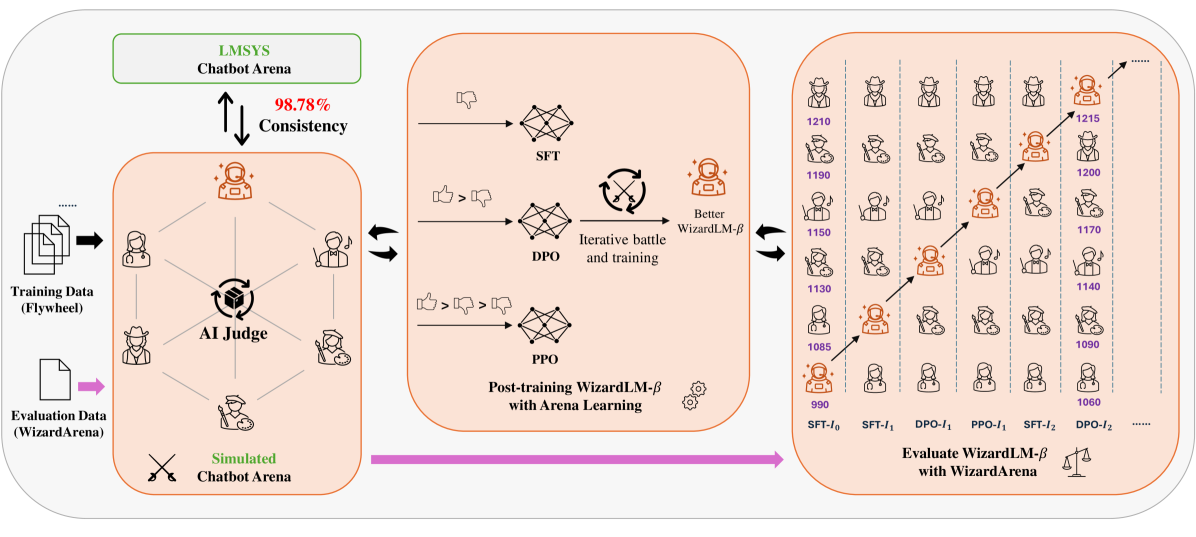
The Arena Learning Pipeline: A closed loop of Battle -> Training Data Generation -> Model Update.
Evaluation Highlights
- 98.79% consistency between WizardArena's offline AI-predicted Elo rankings and human-based LMSys Chatbot Arena rankings
- Outperforms Arena-Hard-v1.0 by +8.58% and MT-Bench by +35.23% in alignment with human preference rankings
- Demonstrates continuous performance improvements across three iterative rounds of SFT, DPO, and PPO training
Breakthrough Assessment
8/10
Highly practical contribution. Successfully automating the 'arena' evaluation to drive iterative training (flywheel) addresses a major bottleneck in LLM development. The high correlation with human ranking verifies the method's reliability.