📝 Paper Summary
Post-Training Quantization (PTQ)
Model Compression
Efficient Inference
ADFQ-ViT enables accurate 4-bit Vision Transformers by tailoring quantization strategies to the specific irregular distributions of post-LayerNorm outliers and asymmetric post-GELU activations.
Core Problem
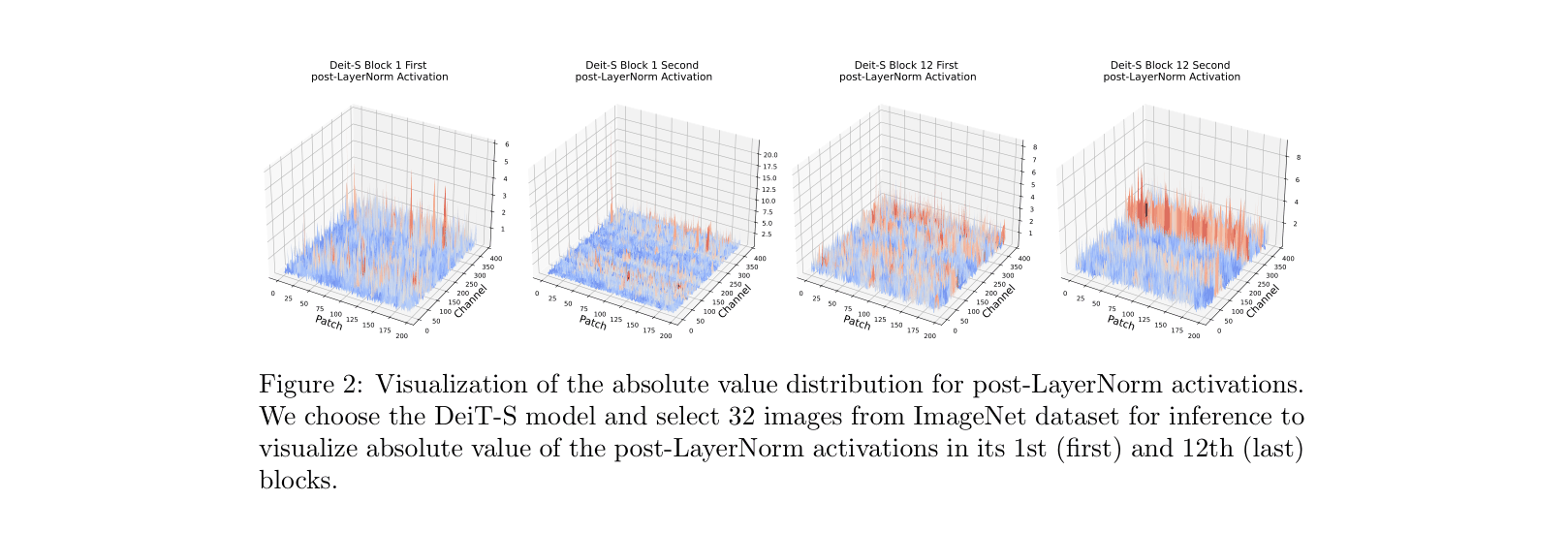
Standard quantization methods fail at low bit-widths (e.g., 4-bit) for Vision Transformers because they cannot handle the extreme outliers in post-LayerNorm activations or the asymmetric distribution of post-GELU activations.
Why it matters:
- Vision Transformers require substantial memory and compute, making deployment on resource-constrained devices difficult without compression
- Existing 4-bit quantization methods for ViTs suffer severe accuracy degradation (e.g., >10% drop), rendering them unusable for practical applications
- Hardware-friendly uniform quantizers are incompatible with the long-tailed and irregular activation distributions inherent to Transformer architectures
Concrete Example:
In a ViT model, post-LayerNorm activations contain rare but extreme outliers. A standard uniform quantizer must stretch its range to include these outliers, causing the vast majority of normal values to be mapped to the same few integers, resulting in massive precision loss and accuracy collapse.
Key Novelty
Activation-Distribution-Friendly Quantization (ADFQ)
- Separates sparse outliers from dense normal values in post-LayerNorm activations, keeping outliers in full precision while quantizing the rest with high granularity (Per-Patch)
- Shifts asymmetric post-GELU activations (which are mostly negative) into the positive domain to fully utilize the resolution of a Log2 quantizer, then shifts them back
- Fine-tunes quantization parameters by minimizing the error in Attention Scores and module outputs, ensuring the critical self-attention mechanism remains accurate
Architecture
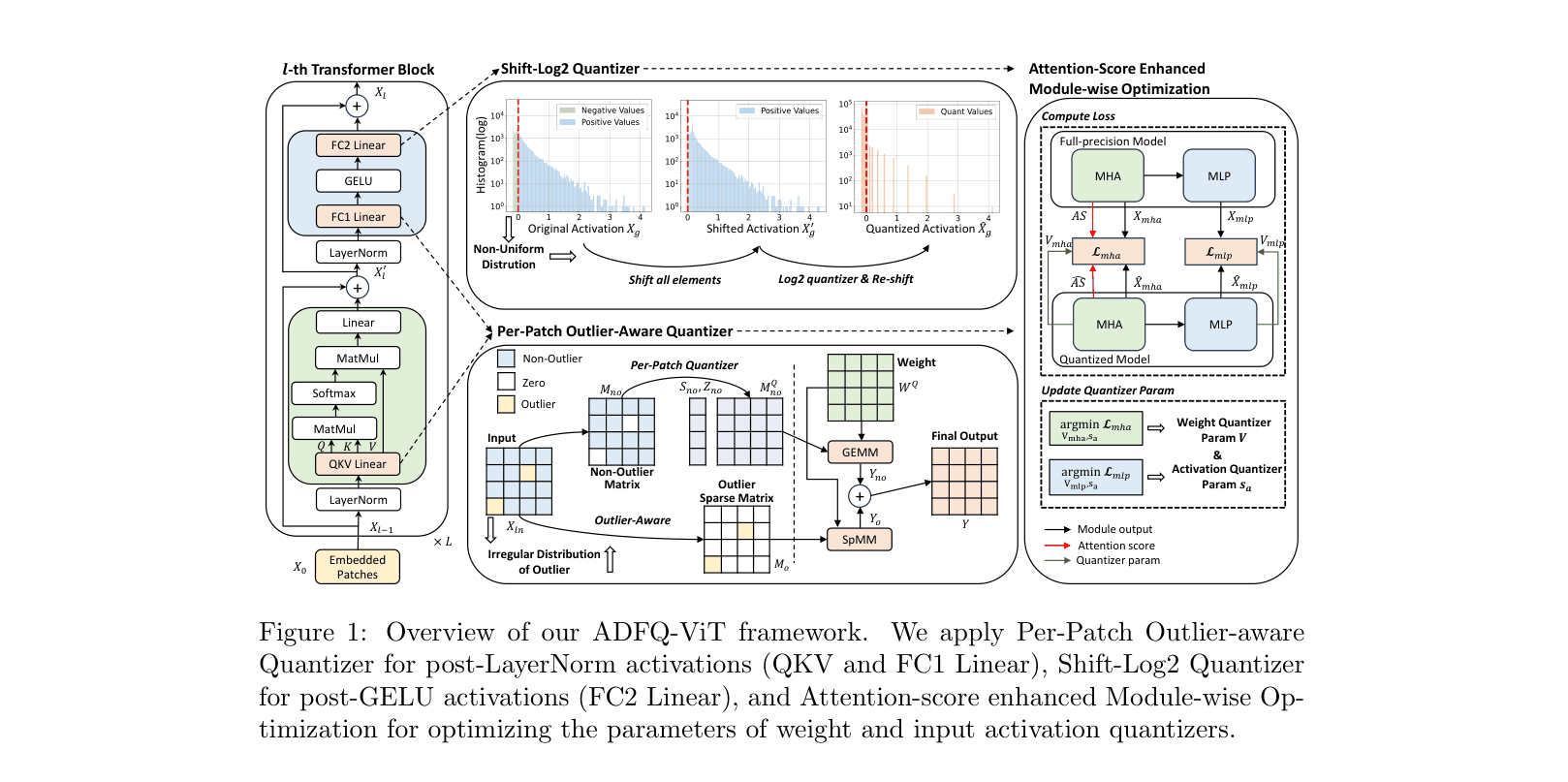
Overview of the ADFQ-ViT framework showing the quantization pipeline for a Transformer block.
Evaluation Highlights
- +10.23% Top-1 accuracy improvement on ImageNet for ViT-B (4-bit quantization) compared to the state-of-the-art RepQ-ViT
- +6.03% Top-1 accuracy improvement on ImageNet for DeiT-S (4-bit quantization) over RepQ-ViT
- Achieves near-lossless performance at 6-bit quantization (avg. drop of only 0.67% vs. full-precision) across ViT, DeiT, and Swin Transformer models
Breakthrough Assessment
8/10
Addresses a critical bottleneck in 4-bit ViT quantization with a highly effective, distribution-aware approach. The accuracy gains on standard benchmarks are exceptionally large compared to prior art.