📝 Paper Summary
Positional Encoding
Algorithmic Reasoning
Long-Context Modeling
TAPE enhances transformers by contextualizing positional embeddings with sequence content layer-by-layer while enforcing permutation and orthogonal equivariance to ensure stability and better algorithmic reasoning.
Core Problem
Existing positional encodings (like RoPE or ALiBi) are either static or enforce rigid decay patterns, limiting the model's ability to perform flexible position-based addressing required for complex algorithmic reasoning.
Why it matters:
- Tasks like arithmetic and logical reasoning rely heavily on precise position-based addressing rather than just content similarity
- Rigid locality biases in current methods (e.g., decay based on relative distance) hinder long-range dependency modeling
- Standard transformers without context-aware positioning are theoretically limited in the class of algorithms they can represent (cannot solve NC1-complete problems)
Concrete Example:
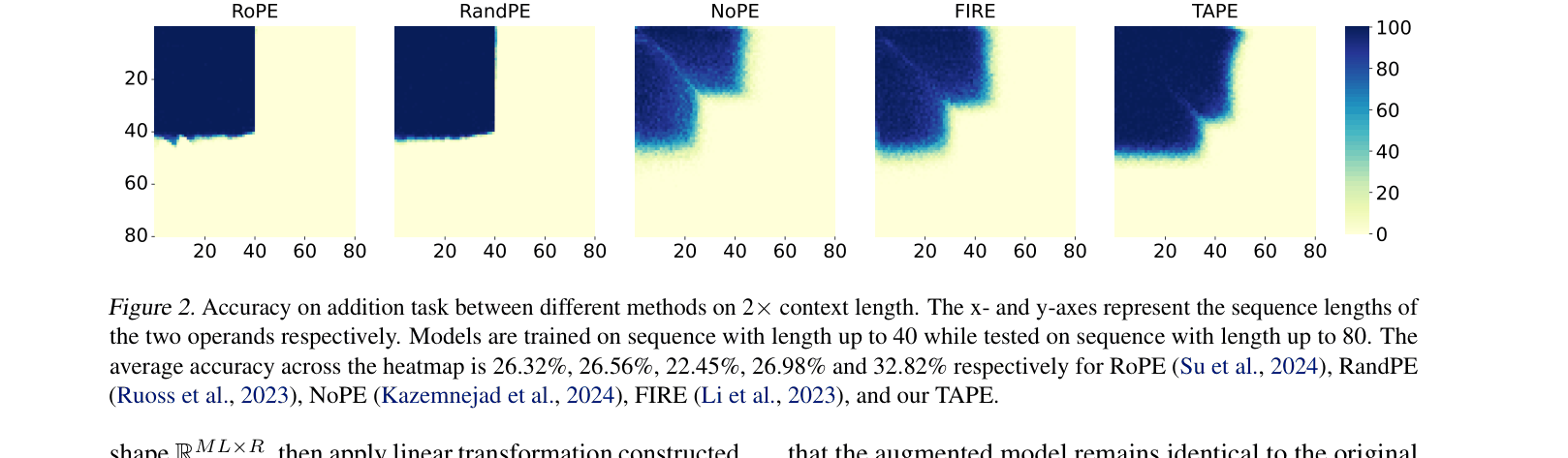
In arithmetic addition, every digit is equally important regardless of distance, but standard decay-based encodings (like ALiBi) downweight distant tokens. TAPE allows dynamic reweighting, enabling accurate retrieval of distant operands where static methods fail.
Key Novelty
Contextualized Equivariant Positional Encoding (TAPE)
- Treats positional encodings as dynamic states that are updated layer-by-layer using sequence content (via attention and MLPs), rather than fixed inputs
- Enforces mathematical symmetry (permutation and orthogonal equivariance) on these updates to ensure that positional information remains relative and stable even as it evolves with context
Architecture
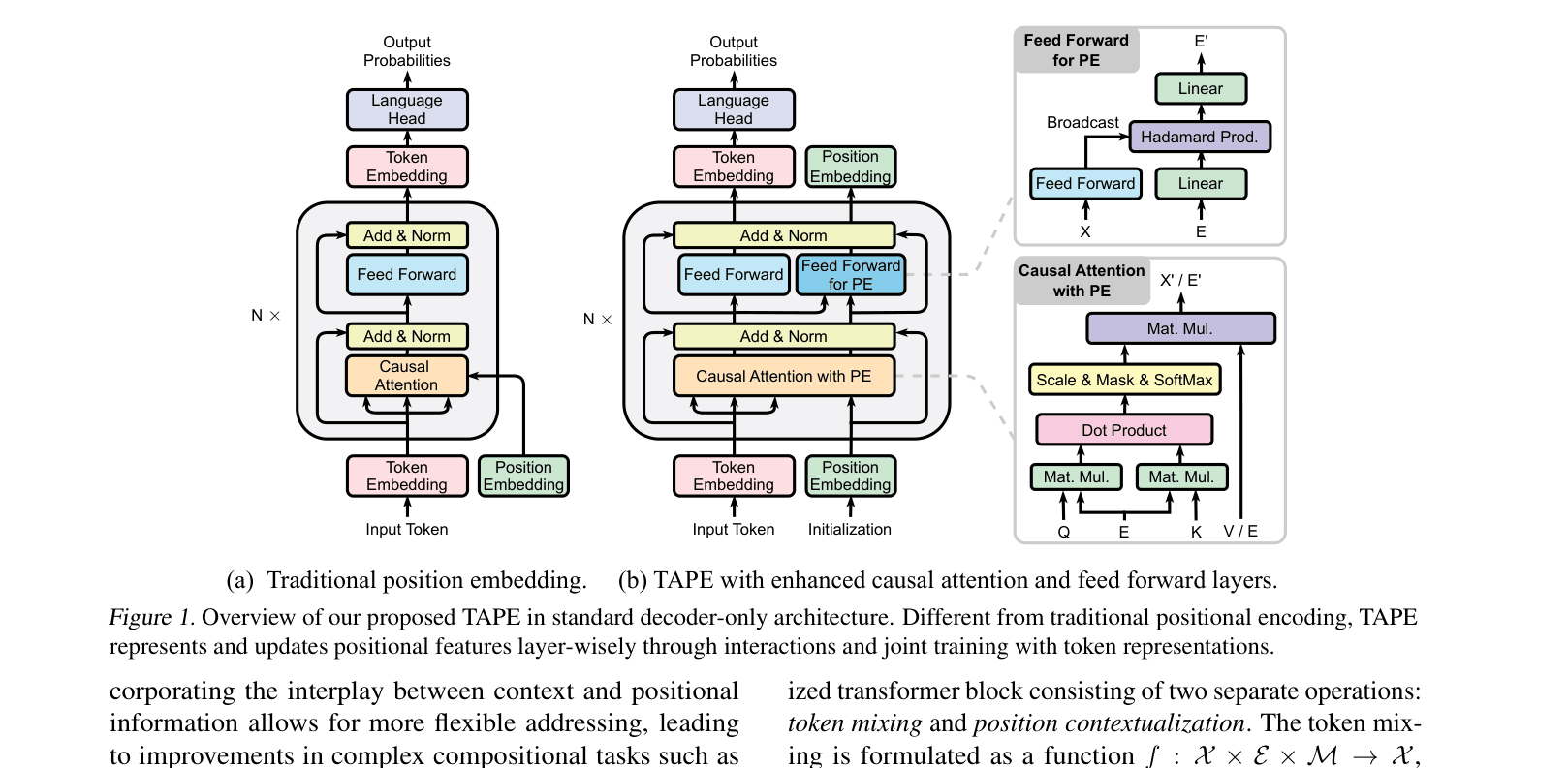
Comparison between traditional transformer architecture and TAPE. It details the data flow where positional embeddings are updated layer-by-layer alongside token embeddings.
Evaluation Highlights
- Achieves 32.82% average accuracy on arithmetic addition tasks, outperforming FIRE (26.98%) and RoPE (26.32%) with better length generalization
- State-of-the-art perplexity on PG-19 long-context modeling (7.063 at 8k length), surpassing LongLoRA (8.645) and Theta Scaling (7.999)
- Near-perfect accuracy (~1.0) on passkey retrieval tasks up to 8k context length, matching full-parameter methods despite using parameter-efficient fine-tuning
Breakthrough Assessment
8/10
Theoretically grounds positional encoding in circuit complexity (NC1 completeness) and provides a practical, drop-in equivariant architecture that significantly improves arithmetic and long-context performance.