📝 Paper Summary
Post-Training Quantization (PTQ)
Model Compression
Efficient Inference
MagR optimizes pre-trained weights via a channel-wise L_infinity-regularized objective to reduce weight magnitudes and outliers before quantization, improving low-bit performance without adding inference overhead.
Core Problem
Post-Training Quantization (PTQ) often degrades performance significantly at ultra-low precision (<4-bit) due to outliers and large weight magnitudes.
Why it matters:
- Existing solutions like QuIP or AWQ use linear transformations that require inverse operations on activations during inference, adding computational overhead.
- Large Language Models (LLMs) are memory-bandwidth bound; reducing weight bit-width is crucial for deployment but must not slow down token generation with extra processing.
- Achieving high accuracy at 2-3 bits without retraining (QAT) remains a major challenge for deploying LLMs on resource-constrained devices.
Concrete Example:
Current methods like QuIP transform weights (W) by multiplying with a matrix T (T*W), requiring the input features X to be multiplied by T inverse (X*T^-1) during inference. This extra multiplication slows down generation. MagR changes W directly without requiring any operation on X.
Key Novelty
Optimization-based Weight Magnitude Reduction (MagR)
- Exploits the observation that feature matrices in LLMs are rank-deficient, meaning multiple weight configurations can produce the same output.
- Finds a specific weight configuration that preserves layer outputs while minimizing the maximum weight magnitude (L_infinity norm) to make weights quantization-friendly.
- Implements a non-linear transformation via proximal gradient descent that alters weights permanently before quantization, requiring no auxiliary operations during inference.
Architecture
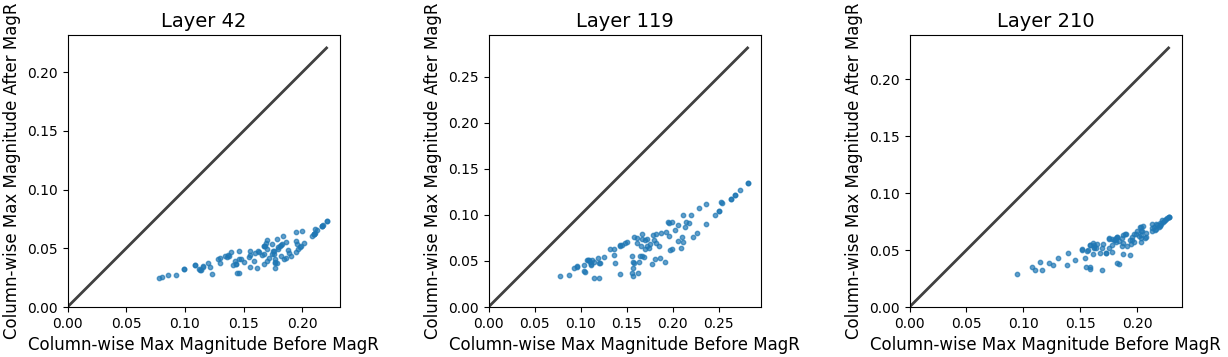
Visualization of weight magnitudes before and after MagR preprocessing.
Evaluation Highlights
- Achieves 5.95 perplexity on LLaMA2-70B with INT2 quantization (W2A16), outperforming RTN (6.81) and matching or beating complex baselines like AWQ.
- Preprocessing takes only ~15 minutes for LLaMA2-7B and ~3.5 hours for LLaMA2-70B on a single A100 GPU.
- MagR + OPTQ significantly boosts INT2 performance, lowering perplexity on LLaMA2-13B from >1000 (RTN) to 6.74 on Wikitext2.
Breakthrough Assessment
7/10
Provides a mathematically elegant solution to the overhead problem in PTQ. While performance gains are comparable to SOTA, the zero-overhead inference is a significant practical advantage.