📝 Paper Summary
Efficient Diffusion Models
Model Quantization
PTQD enables accurate low-bit diffusion models without retraining by disentangling quantization noise into correlated and uncorrelated components for separate correction and using step-aware mixed precision to preserve signal-to-noise ratio.
Core Problem
Directly quantizing diffusion models creates noise that biases the estimated mean and clashes with the variance schedule, while accumulating errors lead to severe SNR degradation in later denoising steps.
Why it matters:
- Diffusion models are computationally expensive and slow, but their iterative nature makes them uniquely sensitive to quantization noise compared to single-step models like CNNs
- Existing Post-Training Quantization (PTQ) methods treat diffusion models as generic networks, ignoring the specific signal-to-noise ratio requirements of the denoising process
- Retraining (Quantization-Aware Training) is resource-intensive; effective PTQ is needed for deployment on edge devices
Concrete Example:
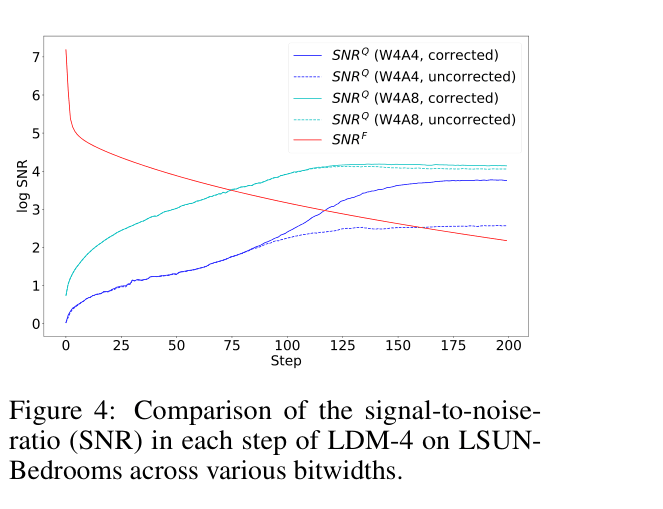
When quantizing Stable Diffusion to 4-bit (W4A8) using standard methods like Q-Diffusion, generated faces on CelebA-HQ appear corrupted with severe artifacts (Figure 1). In late denoising steps, the signal-to-noise ratio of a W4A4 model drops to near 1, meaning the quantization noise is as strong as the signal itself.
Key Novelty
Unified Quantization Noise Correction & Step-Aware Mixed Precision
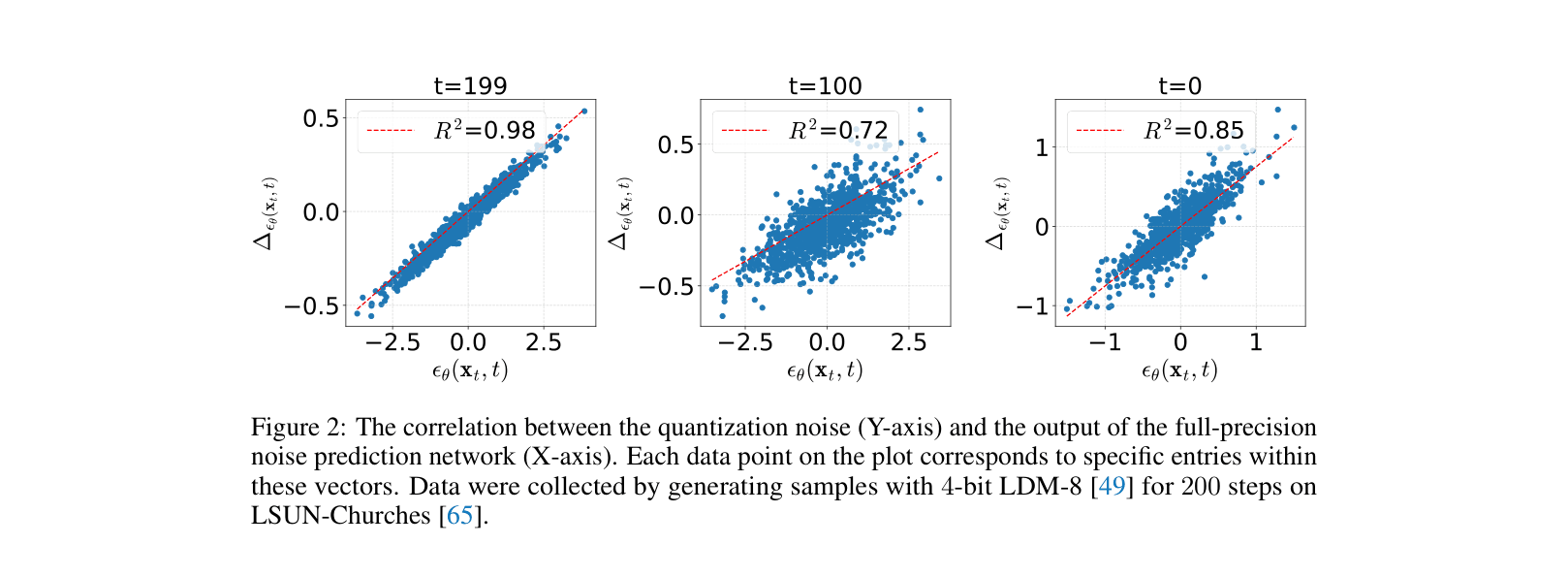
- Disentangles quantization noise into a correlated part (linearly related to the signal) and an uncorrelated residual; corrects the former by rescaling and the latter by bias subtraction
- Calibrates the diffusion variance schedule to 'absorb' the extra variance from uncorrelated quantization noise, effectively hiding the error within the generative process's inherent stochasticity
- Allocates higher activation bitwidths only to later denoising steps where Signal-to-Noise Ratio (SNR) is critical, using lower bitwidths elsewhere to maximize speed
Architecture

The workflow for correcting quantization noise during the diffusion sampling process
Evaluation Highlights
- Achieves 6.44 FID on ImageNet 256x256 with mixed precision (W4A8/W4A4), outperforming state-of-the-art Q-Diffusion (9.97 FID) by a large margin
- Matches full-precision performance on ImageNet (W4A8) with only +0.06 FID increase while reducing bit operations by 19.96x
- Prevents catastrophic failure on LSUN-Churches (mixed precision), achieving 17.99 FID versus Q-Diffusion's 218.59 FID
Breakthrough Assessment
8/10
Offers a mathematically grounded solution to diffusion quantization by leveraging the generative process's own variance parameters. The performance retention at 4-bit weights is remarkable compared to prior baselines.