📝 Paper Summary
End-to-End Autonomous Driving
Vision-Language Models (VLMs) for Control
Poutine adapts an off-the-shelf VLM for driving by predicting trajectories as text tokens, using large-scale vision-language-trajectory pre-training followed by lightweight reinforcement learning on human preferences.
Core Problem
Long-tail driving scenarios (e.g., rare accidents, construction) are safety-critical but scarce in training data, requiring high-level reasoning that standard planners and nominal-driving VLMs often lack.
Why it matters:
- Rare long-tail events dominate operational risk in autonomous driving but account for less than 0.003% of daily driving data
- Current VLM driving agents are mostly tested on nominal benchmarks (nuScenes) where semantic reasoning is less critical
- Prior methods often require complex custom architectures (heads/tokenizers) that may hinder the VLM's native reasoning capabilities
Concrete Example:
In a 'Spotlight' scenario (manually selected challenging cases), a standard planner might fail to infer the intent of a pedestrian or construction cone placement, whereas Poutine leverages VLM reasoning to generate a safe trajectory.
Key Novelty
Simple VLM-based Driving Policy with GRPO
- Treats trajectory prediction purely as a next-token prediction task (text generation) using an unmodified off-the-shelf VLM, avoiding custom action heads
- Combines large-scale self-supervised Vision-Language-Trajectory (VLT) pre-training with Group Relative Policy Optimization (GRPO), a lightweight RL method using human preferences
Architecture

The two-stage training pipeline (VLT Pre-training followed by RL Post-training) and the inference data flow
Evaluation Highlights
- Achieves 7.99 Rater Feedback Score (RFS) on the Waymo Vision-Based End-to-End Driving Test Set, securing 1st place in the 2025 Challenge
- Outperforms the Waymo Baseline by +0.46 RFS points on the test set
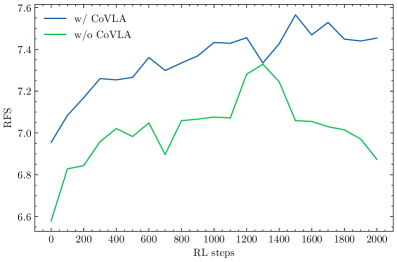
- Demonstrates zero-shot cross-continent transfer: a model trained solely on Japanese data (CoVLA) achieves 7.74 RFS on US data (Waymo)
Breakthrough Assessment
9/10
Achieves SOTA on a rigorous long-tail benchmark using a surprisingly simple recipe (standard VLM + GRPO), proving complex custom architectures are unnecessary for strong driving performance.