📝 Paper Summary
Mixture-of-Experts (MoE)
Model Sparsification
Post-Training / Instruction Tuning
LLaMA-MoE v2 converts instructed dense LLMs into sparse MoE models by partitioning both Attention and MLP neurons, using a two-stage post-training strategy to recover performance without expensive pre-training.
Core Problem
Converting dense models to MoE typically requires resource-intensive continual pre-training and often neglects sparsity in the attention module.
Why it matters:
- Standard dense models activate all parameters, limiting scaling efficiency compared to sparse models
- Existing 'sparse upcycling' methods often duplicate parameters (increasing size) and require massive compute to retrain
- Ignoring attention sparsity misses optimization opportunities, especially given the heterogeneity of attention head patterns
Concrete Example:
Previous methods like Sparse Upcycling copy MLP layers to create experts, inflating the model size and necessitating heavy pre-training. LLaMA-MoE v2 instead partitions the existing neurons of an LLaMA-3-8B-Instruct model and recovers capabilities using only lightweight instruction tuning.
Key Novelty
Post-Training Oriented MoE Construction (Attention & MLP)
- Constructs 'Attention MoE' by grouping attention heads into experts (respecting Grouped Query Attention constraints) and 'MLP MoE' by partitioning neurons based on importance.
- Introduces a 'Residual MLP MoE' variant where common knowledge is extracted into a shared expert while other neurons form routed experts.
- Employs a two-stage post-training pipeline (General -> Math/Code) to recover the performance of the sparsified instructed model.
Architecture
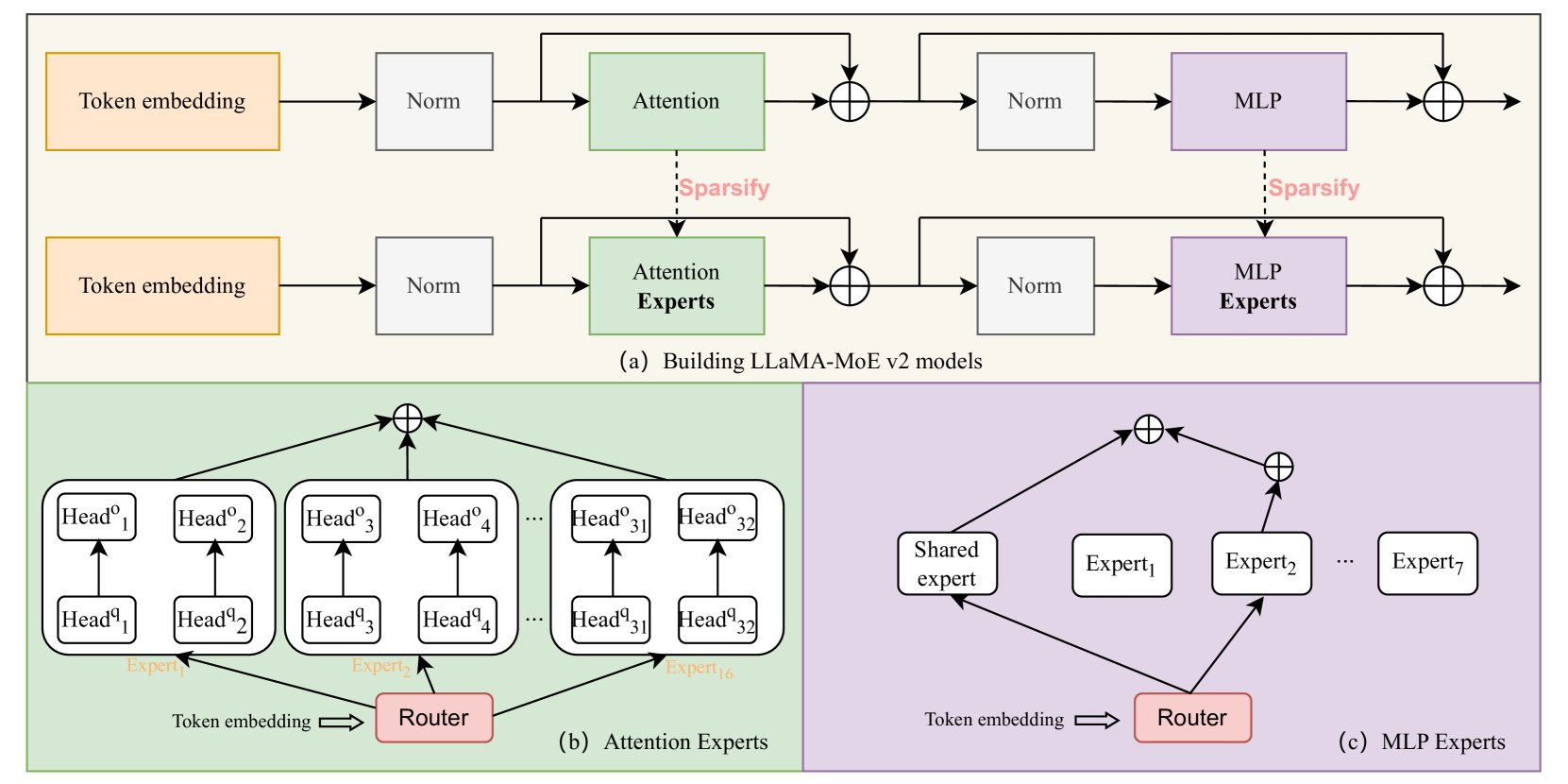
The overall framework for constructing LLaMA-MoE v2. It illustrates the conversion of Dense Attention and MLP blocks into their MoE counterparts and the subsequent two-stage post-training pipeline.
Breakthrough Assessment
7/10
Proposes a novel, cheaper pathway to MoE models (sparsifying instructed models + post-training) and addresses Attention sparsity, which is often overlooked. Impact depends on the (missing) quantitative results.