📊 Experiments & Results
Evaluation Setup
Language modeling and zero-shot tasks
Benchmarks:
- WikiText-2 (Language Modeling (Perplexity))
- C4 (Language Modeling (Perplexity))
- PIQA, ARC, HellaSwag, Winogrande, BoolQ (Zero-shot Common Sense Reasoning)
Metrics:
- Perplexity (PPL)
- Zero-shot Accuracy
- Latency
- Energy Consumption
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Perplexity results on WikiText-2 showing ShiftAddLLM outperforms baselines at low bit-widths. | ||||
| WikiText-2 | Perplexity | 16.30 | 9.60 | -6.70 |
| WikiText-2 | Perplexity | 9.99 | 9.60 | -0.39 |
| Energy consumption analysis for a specific MLP layer. | ||||
| OPT-66B MLP Layer | Energy (Joules) | 80.36 | 9.77 | -70.59 |
| Zero-shot accuracy averages across 5 tasks (PIQA, ARC, HellaSwag, Winogrande, BoolQ). | ||||
| 5-Task Average | Accuracy | 59.83 | 63.38 | +3.55 |
Experiment Figures
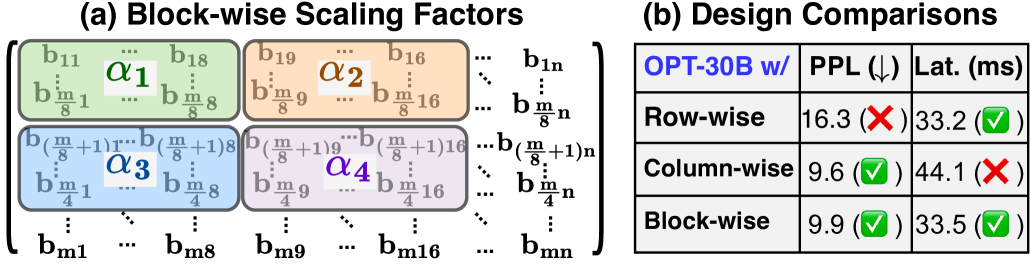
Latency and Perplexity trade-off analysis for Column-wise vs. Block-wise scaling factors on OPT-30B.
Sensitivity analysis of different layers in the Llama-2-7B model to reparameterization.
Main Takeaways
- Consistent perplexity reduction compared to LUT-GEMM and GPTQ at low bit-widths (2-3 bits), validating the multi-objective optimization strategy
- Automated bit allocation effectively handles layer-wise sensitivity, assigning more bits to vulnerable Q/K layers
- Massive energy reductions (>80%) achieved by replacing FP16 multiplications with shift-and-add operations
- Latency is comparable to or better than competitive quantized kernels (LUT-GEMM) due to efficient LUT-based implementation