📝 Paper Summary
Model Compression
Post-Training Quantization (PTQ)
AIQViT improves post-training quantization of Vision Transformers by using learnable low-rank weights to compensate for weight errors and a dynamic focusing quantizer to handle unbalanced post-Softmax activations.
Core Problem
Existing PTQ methods for Vision Transformers underestimate the information loss from weight quantization in fully connected layers and use inefficient logarithmic quantizers for unbalanced post-Softmax activations.
Why it matters:
- The heavy computational and memory costs of ViTs hinder deployment on resource-constrained devices
- Standard quantization leads to significant performance deterioration in ViTs, particularly in low-bit cases (e.g., 3-bit or 4-bit)
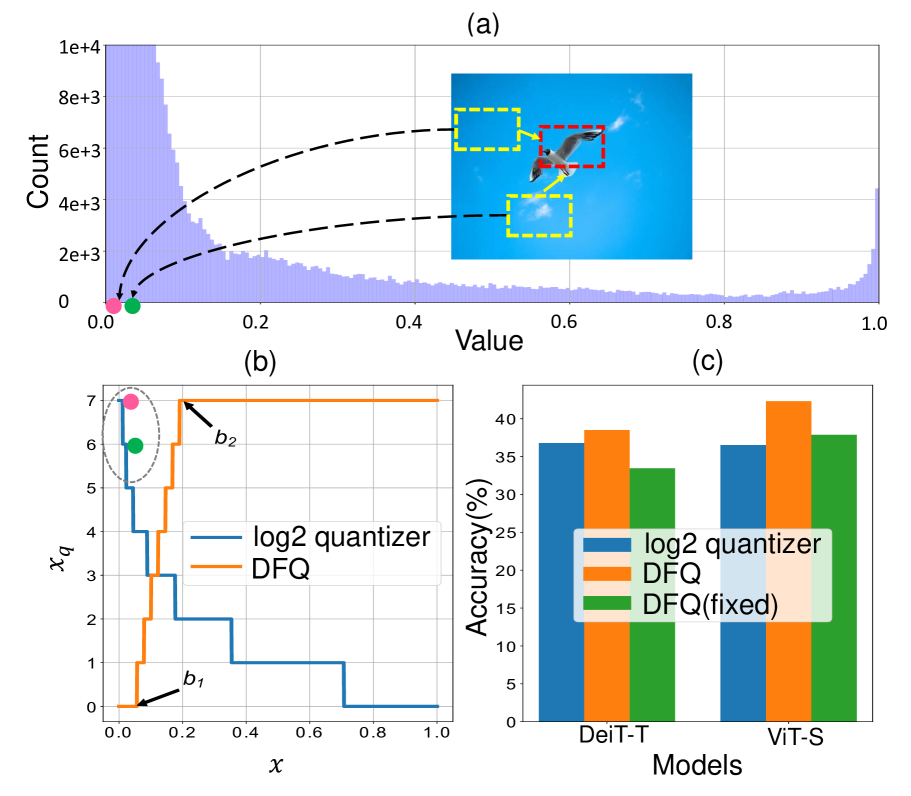
- Logarithmic quantization of Softmax outputs wastes precision on near-zero values that contain redundant information, reducing overall model accuracy
Concrete Example:
In a ViT, the Softmax output has a long-tail distribution. A standard Log2 quantizer assigns high resolution to small values near zero (e.g., 0.0001) which carry little information, while the high-value interval (e.g., 0.9) where the 'attention' actually happens receives lower resolution, degrading the model's ability to distinguish important features.
Key Novelty
Architecture-Informed Low-Rank Compensation & Dynamic Focusing Quantizer
- Introduces learnable low-rank adapters (similar to LoRA) alongside quantized weights to recover information lost during quantization, with ranks determined automatically via neural architecture search
- Replaces static logarithmic quantization for Softmax outputs with a dynamic mechanism that identifies the most valuable value interval and applies uniform quantization only within that focused range
Architecture
Overview of the AIQViT framework illustrating the two main components: Architecture-Informed Low-Rank Compensation and Dynamic Focusing Quantizer.
Evaluation Highlights
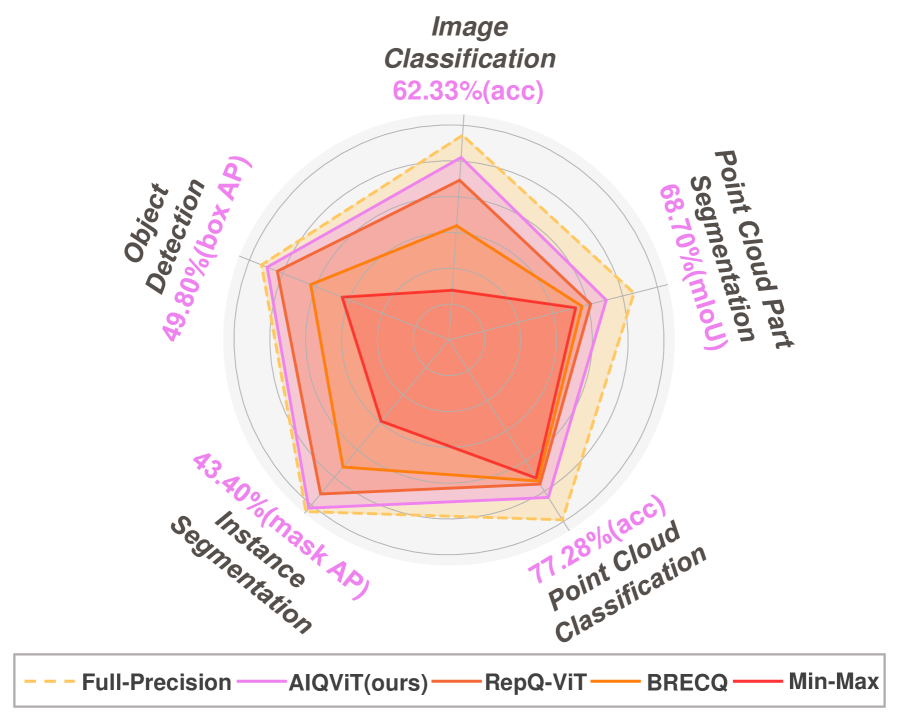
- Outperforms state-of-the-art RepQ-ViT by 1.6% accuracy on ImageNet classification with ViT-S in the ultra-low bit 3-bit weight/3-bit activation setting
- Achieves 81.3% accuracy on ImageNet with ViT-B (4-bit weights/4-bit activations), surpassing the PTQ4ViT baseline of 79.2%
- Demonstrates robust generalization across five different vision tasks, including point cloud classification and object detection
Breakthrough Assessment
7/10
Strong improvements in low-bit regimes (3-bit/4-bit) for ViTs. The combination of NAS-based rank search for compensation and dynamic activation quantization addresses specific ViT bottlenecks effectively.