📝 Paper Summary
Multilingual Machine Translation
LLM Post-training
Parameter-Efficient Fine-Tuning
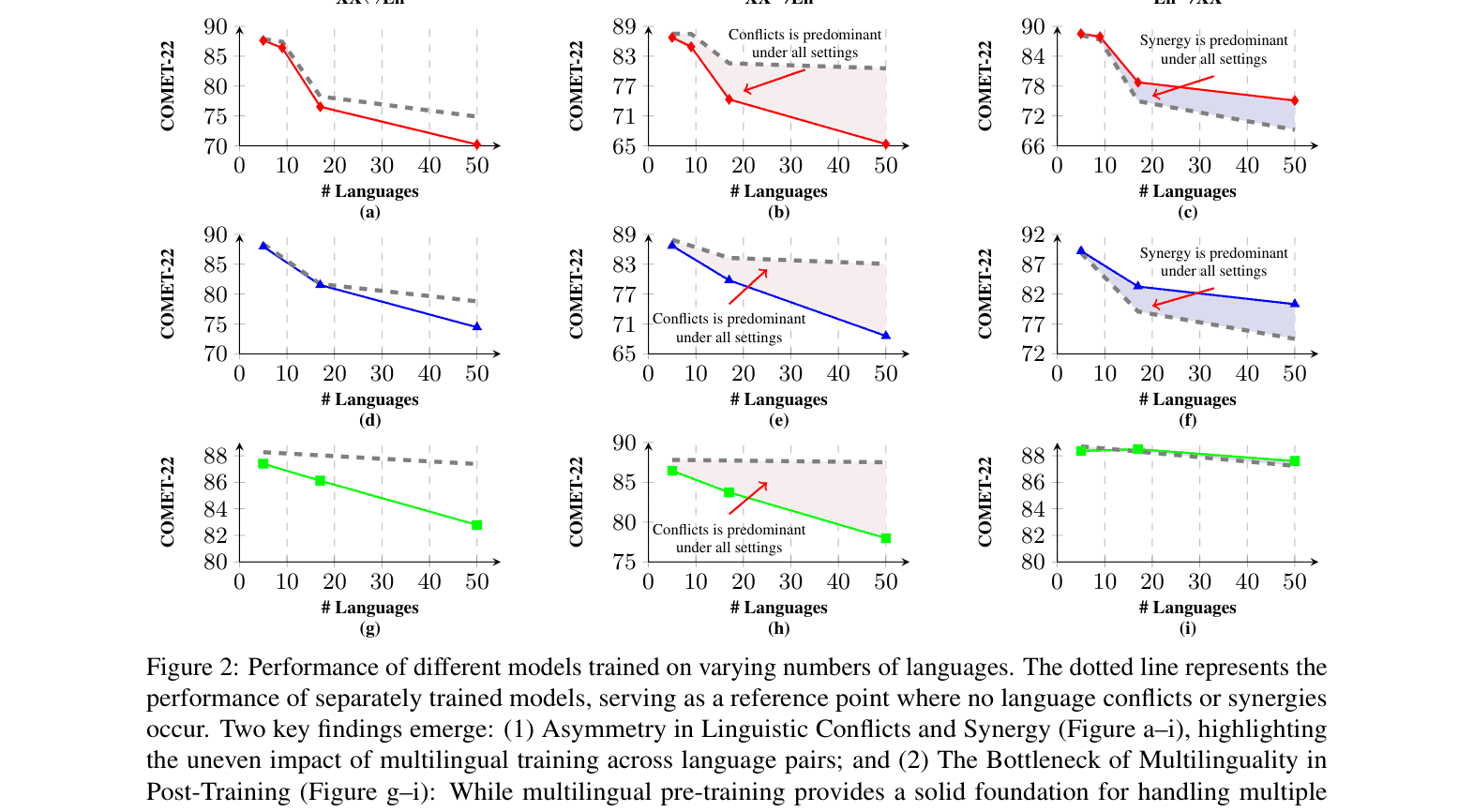
The paper identifies that linguistic conflicts dominate many-to-English translation while synergy benefits English-to-many, proposing a direction-aware training strategy that applies separate training and merging for the former and group training for the latter.
Core Problem
The 'Curse of Multilinguality' (CoM) degrades translation performance as languages scale, and existing solutions like massive scaling are prohibitively expensive.
Why it matters:
- Scaling model size and data budgets to fight CoM is inefficient and inaccessible for many researchers
- Standard multilingual post-training treats all translation directions symmetrically, failing to address that XX→En directions suffer from conflicts while En→XX directions benefit from synergy
Concrete Example:
In German-to-English (XX→En) translation, a model trained on all languages (multilingual) significantly underperforms a model trained only on German-English (separate) due to interference. Conversely, for English-to-German (En→XX), the multilingual model often outperforms the separate one due to positive transfer. Standard training ignores this asymmetry.
Key Novelty
Direction-Aware Training (DAT) with Group-wise Merging
- Decomposes post-training based on translation direction: applies separate training for XX→En directions to minimize conflicts, and group multilingual training for En→XX to maximize synergy
- Uses group-wise model merging (TIES) specifically for the XX→En separate experts to reduce parameter count for deployment, avoiding merging for En→XX where it causes degradation
Architecture
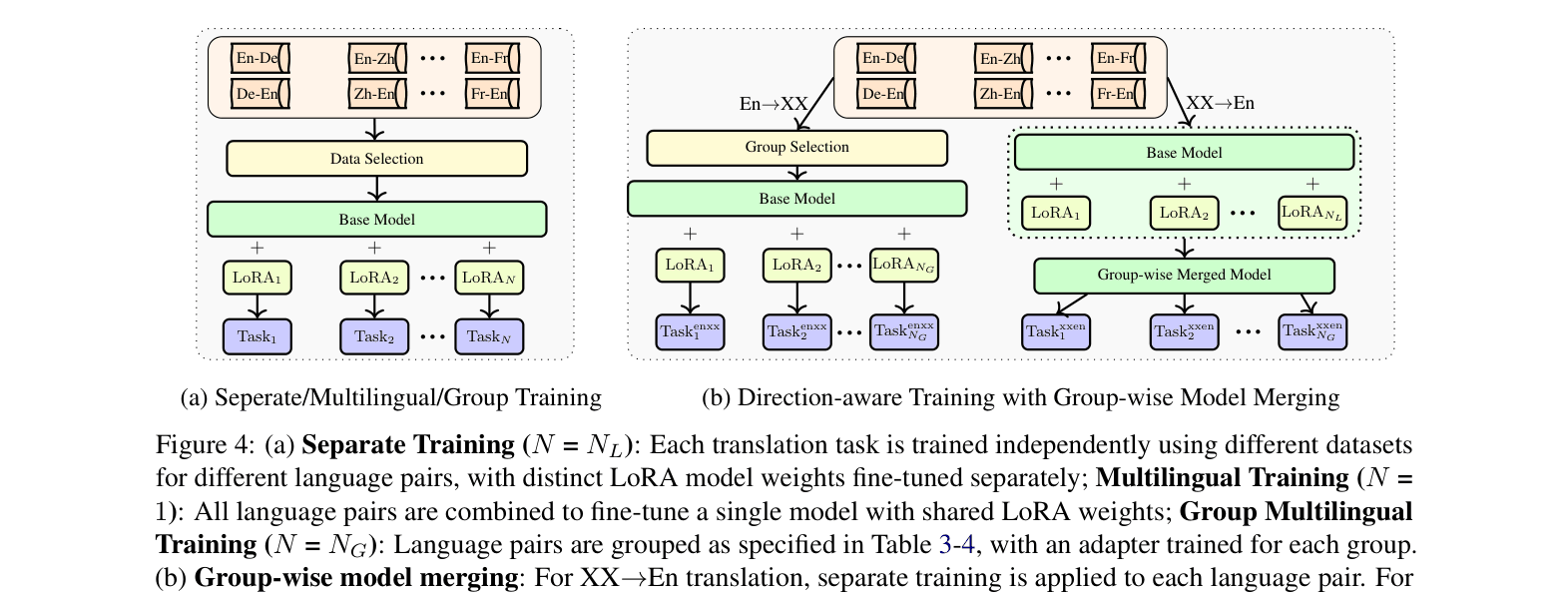
The Direction-Aware Training with Group-wise Model Merging workflow.
Evaluation Highlights
- Achieves comparable performance to X-ALMA-13B (Only SFT) using only 20B pre-training tokens (5.5× fewer than X-ALMA's 110B) and 1.7× fewer parameters
- Outperforms larger baselines like Aya-101 (13B) and LLaMAX (8B) on Flores-200 and WMT23 benchmarks across 50 languages
- Reduces the performance gap between efficient 13B models and computationally expensive MoE systems to within 0.85 COMET points
Breakthrough Assessment
7/10
Strong efficiency gains and a novel, empirically grounded insight into the asymmetry of multilingual transfer. It doesn't beat SOTA raw performance but offers a much cheaper recipe for competitive results.