📝 Paper Summary
LLM Reasoning
Spurious Correlations
Causal Inference
CAPT mitigates reasoning failures by decomposing prediction into event estimation and symbolic intervention, stripping away spurious correlations while preserving logical structure.
Core Problem
LLMs rely on spurious correlations (shortcuts) learned during pre-training, causing catastrophic failure on out-of-distribution (OOD) reasoning tasks where surface features change but logic remains constant.
Why it matters:
- Models fail on domain-specific tasks (e.g., formal causal inference) when entity names are perturbed, even if the underlying logic is identical
- Standard fine-tuning on small datasets often reinforces pre-existing biases or introduces new selection biases rather than teaching true reasoning structure
- Existing bias mitigation focuses on entity bias (e.g., names) but underexplores event-level bias (e.g., 'alarm is set') crucial for complex reasoning
Concrete Example:
In PrOntoQA, GPT-4o-mini achieves 83.5% on commonsense queries but drops to 61.25% on 'anti-sense' queries where rules contradict prior knowledge (e.g., fictitious rules about alarms), revealing reliance on pre-trained semantic shortcuts.
Key Novelty
Causality-Aware Post-Training (CAPT)
- Decomposes the prediction process: leverages the LLM's strong general knowledge to estimate events, then intervenes to replace them with abstract placeholders
- Applies 'Event Intervention' by mapping specific events (e.g., 'Husband sets alarm') to neutral symbols ({symbol_1}) and finally to random letters, blocking semantic shortcuts
- Enforces learning of the invariant logical structure $S$ rather than surface correlations between events $E$ and answers $Y$
Architecture
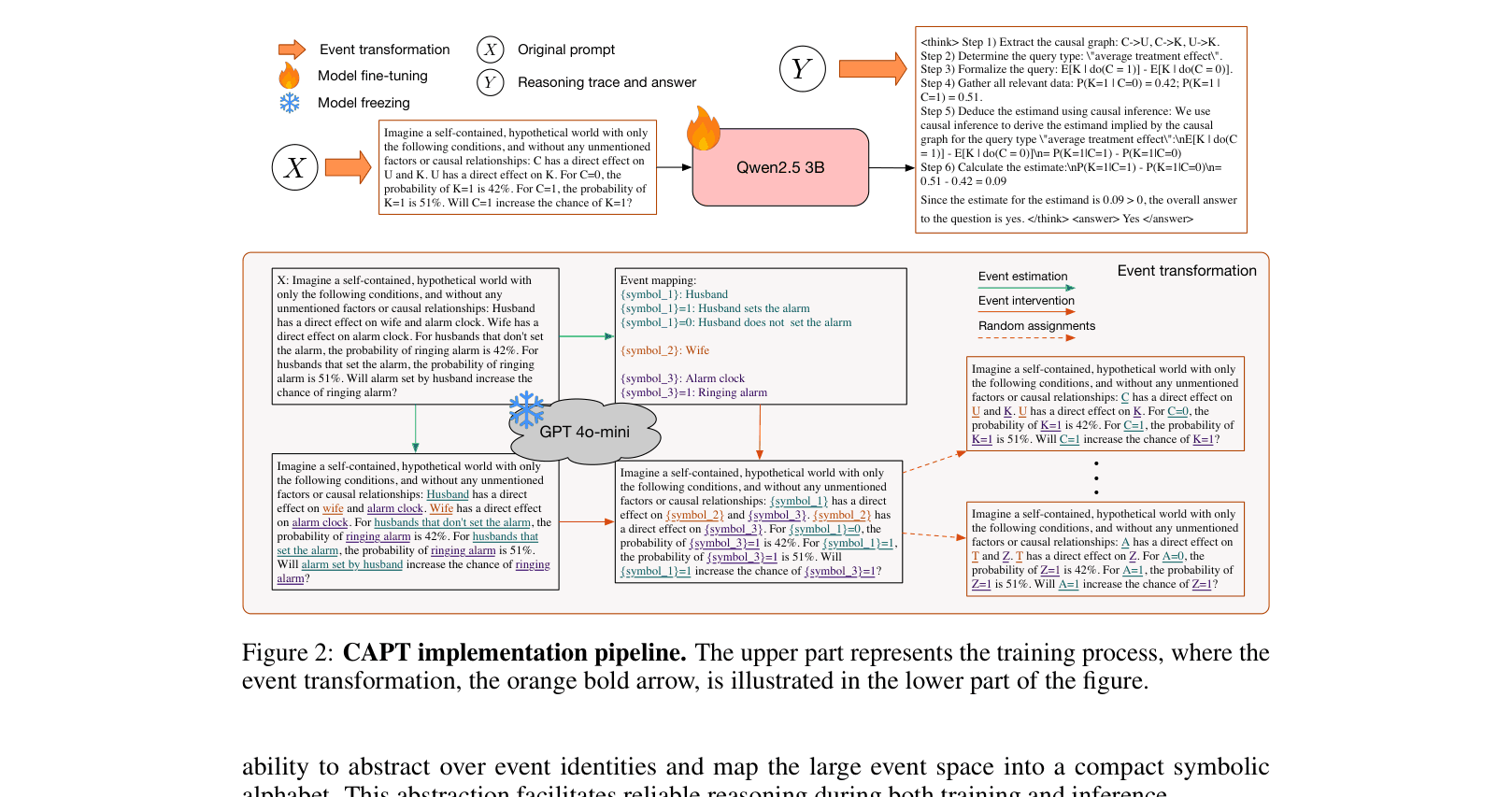
The CAPT implementation pipeline comprising Data Transformation (Training) and Inference adaptation
Evaluation Highlights
- +11.75% accuracy improvement on PrOntoQA OOD (Anti-sense) for Qwen2.5-3B using CAPT with CoT (100 samples) compared to standard CoT fine-tuning
- +9.13% accuracy improvement on CLadder OOD (Anti-sense) for Qwen2.5-3B using CAPT with CoT (100 samples) compared to standard CoT fine-tuning
- Significantly reduced performance standard deviation across distributions (ID vs. OOD), dropping from ~14.8 to 3.4 on PrOntoQA
Breakthrough Assessment
7/10
Simple, theoretically grounded approach that effectively decouples semantic bias from logical reasoning. Strong sample efficiency, though relies on a separate stronger model for the transformation step.