📊 Experiments & Results
Evaluation Setup
RL fine-tuning on math problems followed by evaluation on held-out and OOD benchmarks
Benchmarks:
- Held-out Math Set (Mathematical Reasoning) [New]
- GSM8K (Grade School Math)
- MATH-500 (Challenging Math)
- HumanEval (Code Generation)
- Zebra Puzzle (Logic Puzzle)
Metrics:
- Test Loss (1 - Pass@1)
- Pass@1
- Statistical methodology: Experiments repeated three times; Average Standard Deviation and SEM reported in Appendix
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Data reuse experiments demonstrate that repeating a fixed dataset multiple times is effective up to a specific threshold before overfitting occurs. | ||||
| Held-out Math Set | Test Loss stability | Not reported in the paper | Not reported in the paper | 0 |
| Held-out Math Set | Generalization | Not reported in the paper | Not reported in the paper | Negative |
Experiment Figures
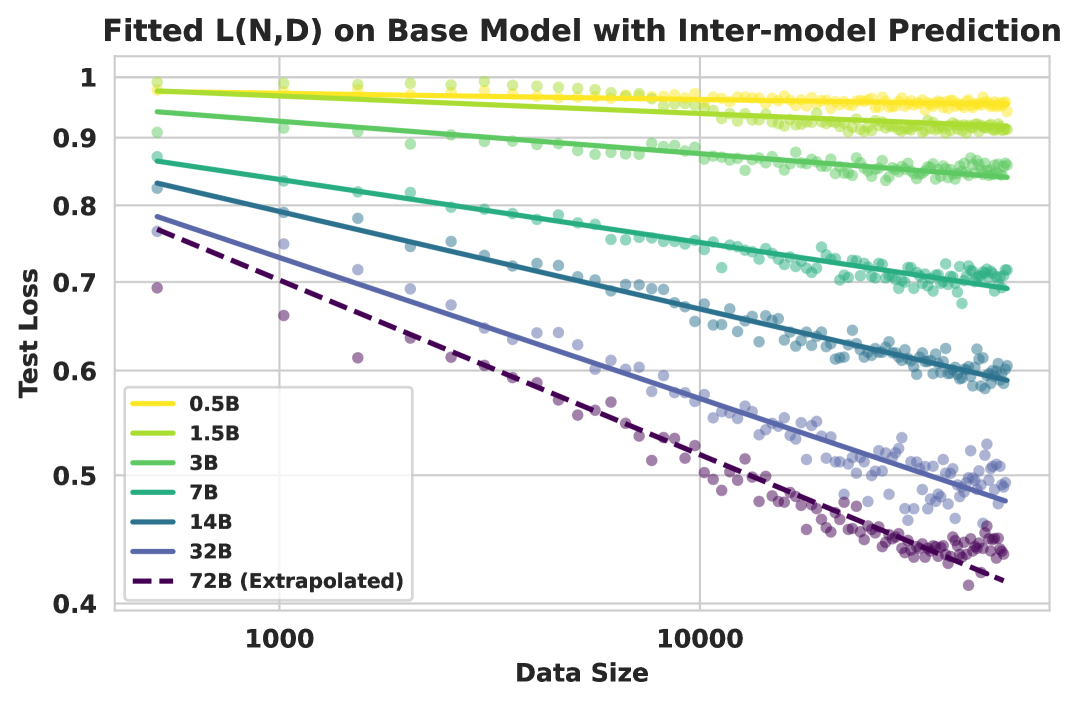
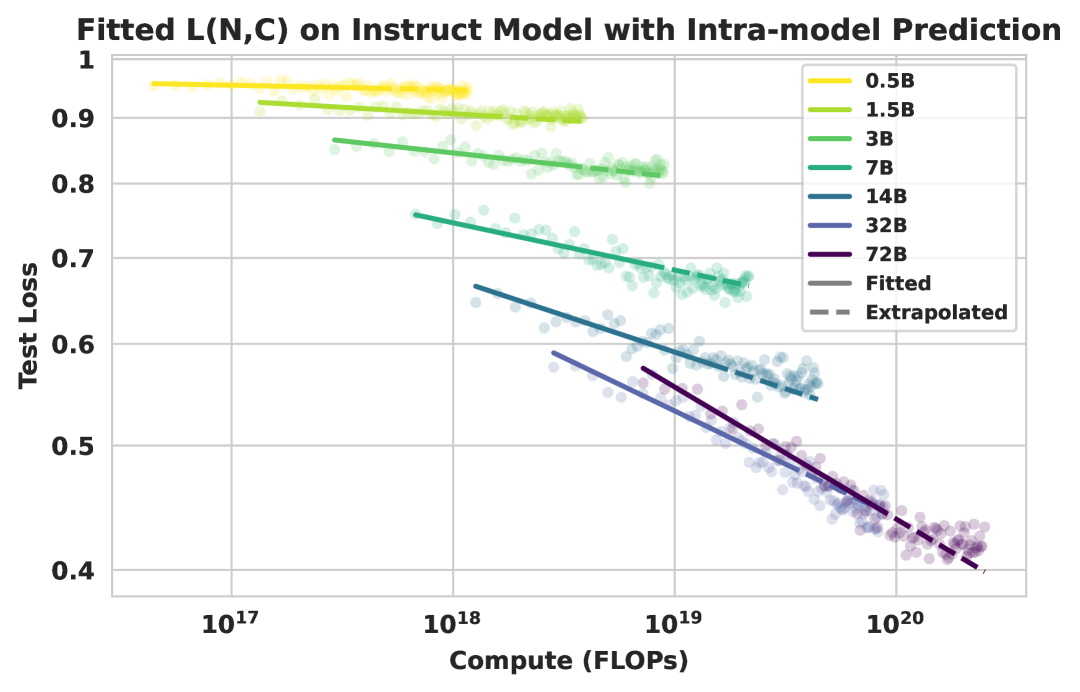
Compute-constrained scaling curves showing Test Loss vs. FLOPs for different model sizes.
Impact of data reuse factor (τ) on final model performance.
Main Takeaways
- Larger models are consistently more compute and data efficient, but the marginal efficiency gains diminish (saturate) as model size increases.
- The relationship between test loss, compute, and data follows a predictable power-law that holds across model scales (0.5B to 72B).
- Data reuse is a highly effective strategy in data-constrained regimes; repeating data up to ~25 times yields similar performance to using unique data.
- RL post-training is highly specialized: while it boosts math performance, it offers little benefit to code or science tasks and can harm general logic reasoning (Zebra Puzzle).