📝 Paper Summary
Safety Alignment
Red Teaming
Small Language Models (SLMs)
Microsoft aligns the Phi-3 small language models using an iterative 'break-fix' cycle combining automated red teaming, manual vulnerability identification, and safety post-training to mitigate risks across multiple languages.
Core Problem
Deploying powerful small language models on-device requires rigorous safety alignment to prevent harmful outputs, but single-round fine-tuning often misses edge cases and emerging threats.
Why it matters:
- Small models (SLMs) running on smartphones enable widespread AI access but must be aligned to human safety preferences to prevent real-world harm
- Standard single-pass safety training often leaves 'jailbreak' vulnerabilities exposed
- Multilingual capabilities introduce new safety risks that English-only red teaming might miss
Concrete Example:
A 'low-skilled adversary' might ask a chatbot directly for harmful content, while an 'intermediate adversary' uses encodings (e.g., base64) or strategies like 'Crescendo' (gradually escalating benign prompts) to bypass standard refusals.
Key Novelty
Iterative 'Break-Fix' Safety Cycle
- Repeats a cycle of red teaming (breaking) and safety post-training (fixing) multiple times, rather than a single alignment phase
- Integrates feedback from both automated tools (PyRIT) and manual red teams directly into dataset curation for the next training round
- Expands red teaming to multilingual contexts (Chinese, Spanish, Dutch) for the Phi-3.5-MoE release to ensure safety transfers across languages
Architecture
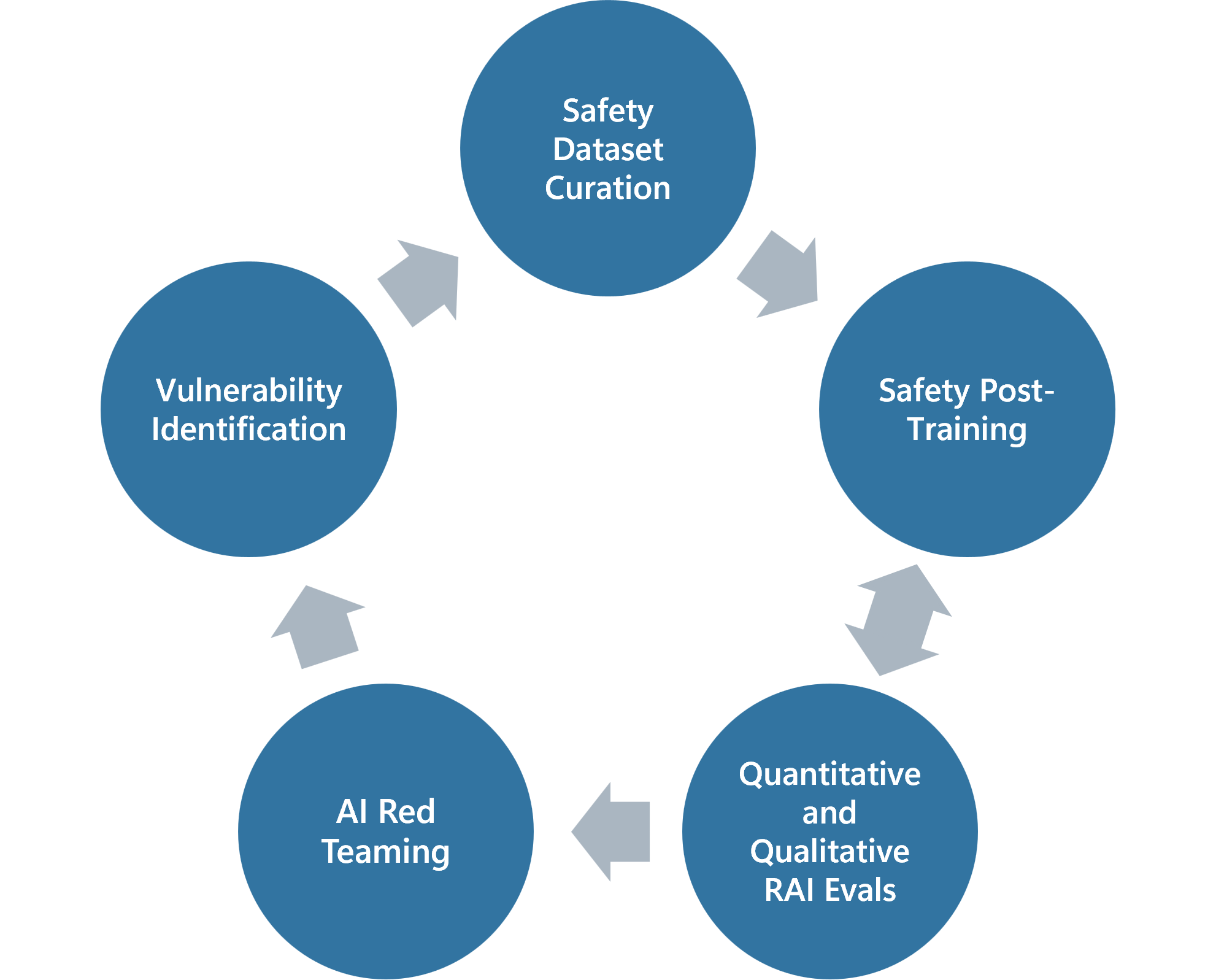
The iterative 'break-fix' safety post-training workflow.
Evaluation Highlights
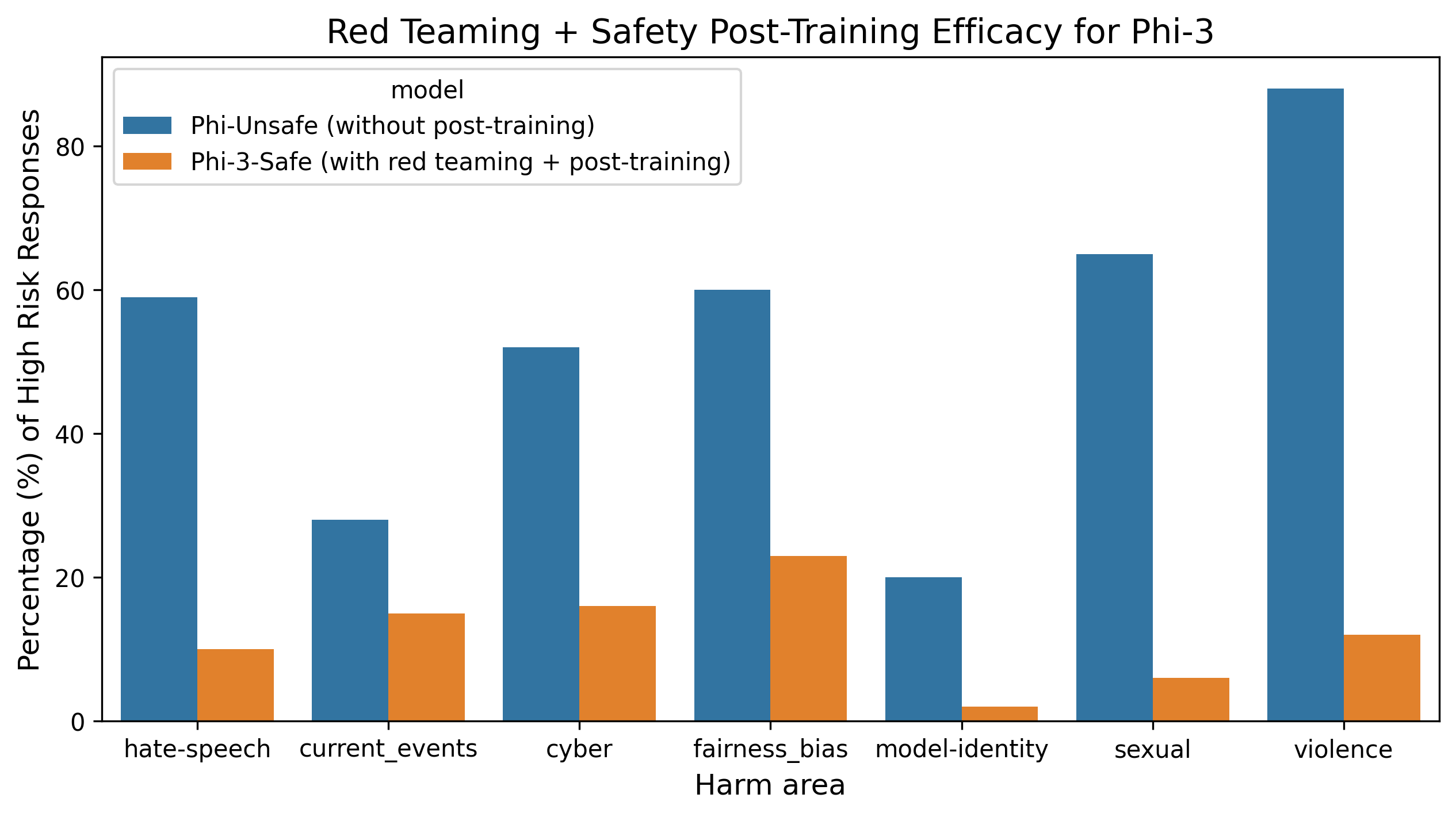
- Phi-3-mini achieves a harmful content continuation defect rate of 0.7%, outperforming Mistral-7B (2.6%) and Gemma-7B (1.3%)
- Achieved ~75% reduction in harmful content generation after multiple rounds of the break-fix cycle compared to the initial baseline
- Phi-3-small achieves 96.5% Inappropriate Prompt Refusal Rate (IPRR) on XSTest, effectively balancing safety with helpfulness
Breakthrough Assessment
7/10
Solid industrial application of iterative safety alignment. While the 'break-fix' concept isn't theoretically new, the rigorous execution and public reporting on SLMs (Phi-3) and multilingual MoEs makes it a valuable case study.