📝 Paper Summary
Distributed Systems for AI
RLHF Infrastructure
DistFlow eliminates the centralized dataflow bottleneck in RLHF training by distributing control and data management across all workers, achieving linear scalability up to 1024 GPUs.
Core Problem
Existing RL frameworks rely on a centralized controller to manage data movement (loading, collection, dispatch), creating a severe I/O bottleneck and memory constraints (OOM) at large scales.
Why it matters:
- Training frontier models requires scaling to thousands of GPUs, but single-controller architectures crash or stall under the massive volume of intermediate data
- Sequential execution in disaggregated architectures (inference vs. training services) causes significant GPU idleness and low utilization
- Rigid, hard-coded pipelines in current systems make it difficult and costly for researchers to experiment with novel algorithmic workflows
Concrete Example:
In a hybrid controller setup (like verl), a single node must collect all generated experiences from thousands of GPUs and dispatch them to training nodes. This 'many-to-one' traffic overwhelms the controller's network bandwidth and memory, causing the system to crash or slow down significantly.
Key Novelty
Fully Distributed Multi-Controller Architecture
- Adopts a multi-controller paradigm where every worker (GPU) manages its own data loading, computation, and transfer, eliminating the central driver node as a bottleneck
- Decouples algorithmic logic from physical execution via a user-defined DAG (Directed Acyclic Graph), which a Planner automatically linearizes and maps to hardware resources
- Uses a Data Coordinator to orchestrate peer-to-peer data redistribution between stages (e.g., changing from Tensor Parallelism to Data Parallelism) without routing through a master node
Architecture
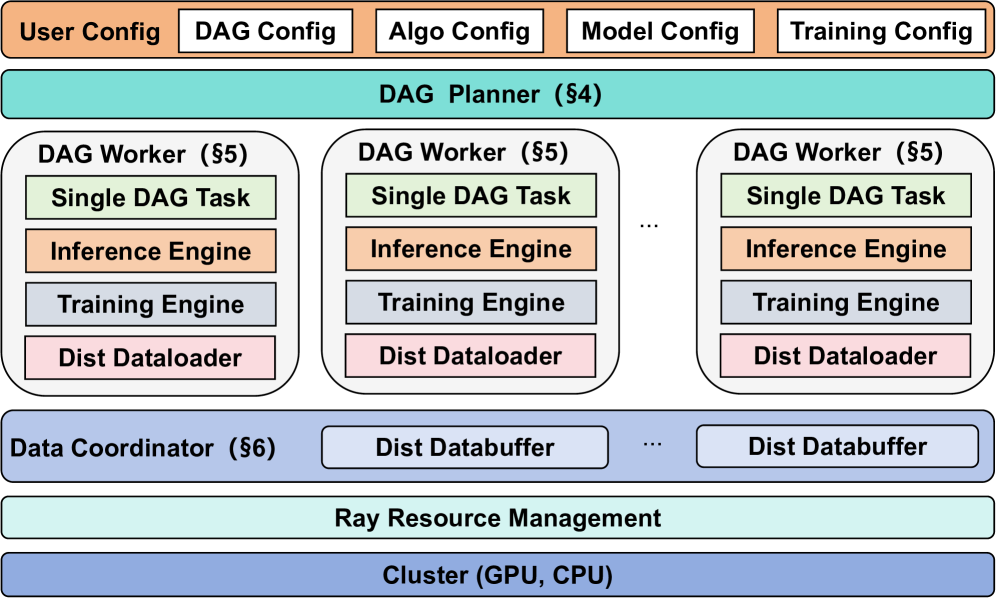
Overview of the DistFlow architecture, highlighting the interactions between the DAG Planner, DAG Workers, and Data Coordinator.
Evaluation Highlights
- Achieves up to 7x improvement in end-to-end training throughput compared to state-of-the-art synchronous frameworks (like OpenRLHF/verl) in specific scenarios
- Demonstrates near-linear scalability from single-node up to 1024 GPUs, avoiding the saturation points typical of centralized controllers
Breakthrough Assessment
8/10
Addresses the critical infrastructure bottleneck for scaling RLHF to massive clusters. Moving from centralized to fully distributed control is a necessary architectural shift for next-gen model training.