📝 Paper Summary
Small Language Models (SLMs)
Model Survey
Efficient AI
This survey analyzes over 160 papers to demonstrate that Small Language Models (1B-8B parameters) can rival or outperform larger foundational models through high-quality data, architectural innovations, and specialized training.
Core Problem
Massive Large Language Models (LLMs) are computationally expensive and resource-intensive, raising the question of whether scale is the only path to high performance.
Why it matters:
- Deploying massive models (>10B parameters) on edge devices or consumer hardware is often infeasible due to memory and compute constraints
- Training and inference costs for LLMs are prohibitively high for many researchers and smaller organizations
- Standard definitions and benchmarks for Small Language Models (SLMs) are lacking, making it difficult to assess their true capabilities relative to LLMs
Concrete Example:
While GPT-4 performs exceptionally well, a 13B parameter model like Llama 2 typically requires significant resources. However, newer SLMs like Mistral 7B can outperform Llama 2 13B on benchmarks, yet there is no unified view explaining how these smaller models achieve such efficiency.
Key Novelty
Comprehensive Survey and Definition of Small Language Models (SLMs)
- Defines SLMs as general-purpose language models with 1B to 8B parameters, distinguishing them from narrow task-specific models and massive LLMs
- Categorizes SLMs into task-agnostic (general purpose) and task-specific families, highlighting architectural trends like State Space Models (SSMs) and Mixture of Experts (MoE)
- Identifies key enablers for SLM performance: high-quality synthetic data, knowledge distillation from larger models, and architectural efficiency (e.g., grouped-query attention)
Architecture
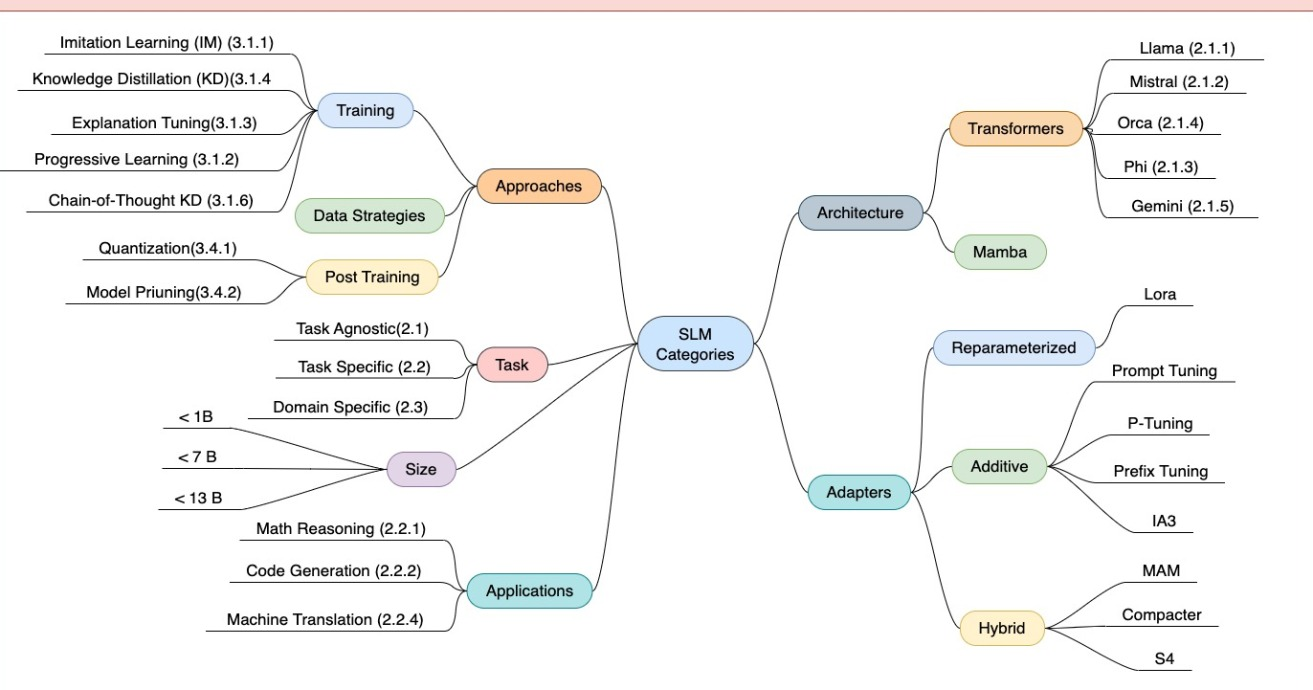
A mind map categorizing Small Language Models (SLMs) into different families based on size, application domains, and training techniques.
Evaluation Highlights
- Mistral 7B outperforms Llama 2 13B on multiple tasks and Llama 1 34B in math and code generation
- Phi-2 (2.7B) achieves performance comparable to Llama-2 70B on reasoning and language understanding benchmarks
- Phi-4 outperforms Qwen 2.5 14B on MMLU (84.8 vs 77.9) and MATH (80.4 vs 44.6) despite being a smaller model class
Breakthrough Assessment
8/10
This is a survey paper rather than a new method, but it provides a critical consolidation of the rapidly evolving SLM landscape, validating the shift from pure scaling laws to data quality and architectural efficiency.