📝 Paper Summary
Model Compression
Post-Training Quantization (PTQ)
Vision Transformers
PTQ4SAM is a post-training quantization framework for the Segment Anything Model that resolves activation outliers by mathematically transforming bimodal distributions into normal ones and using adaptive granularity for attention scores.
Core Problem
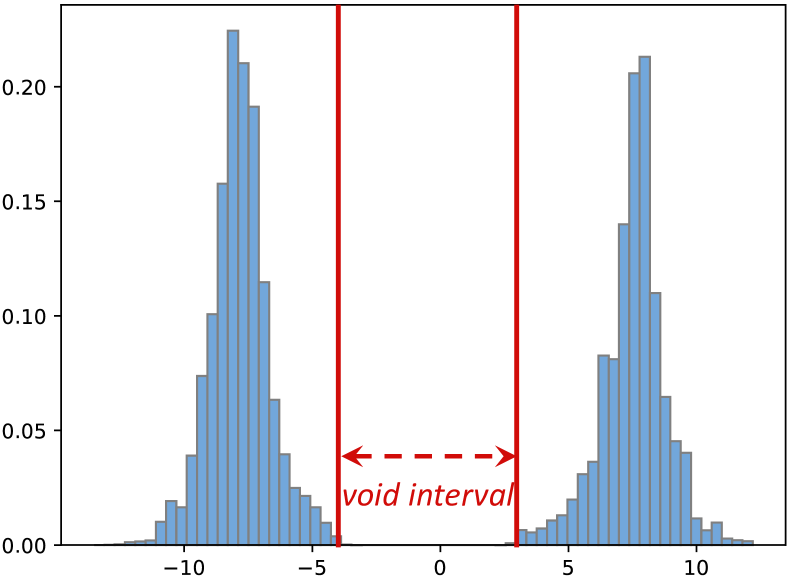
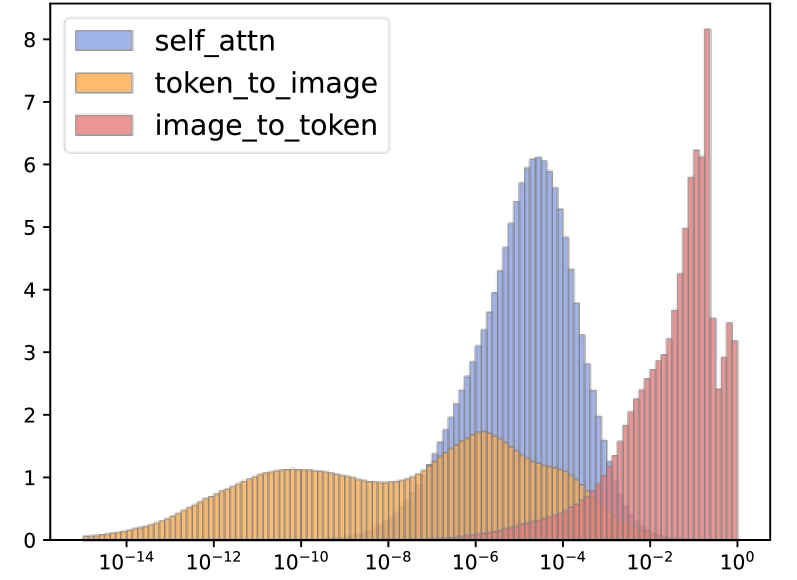
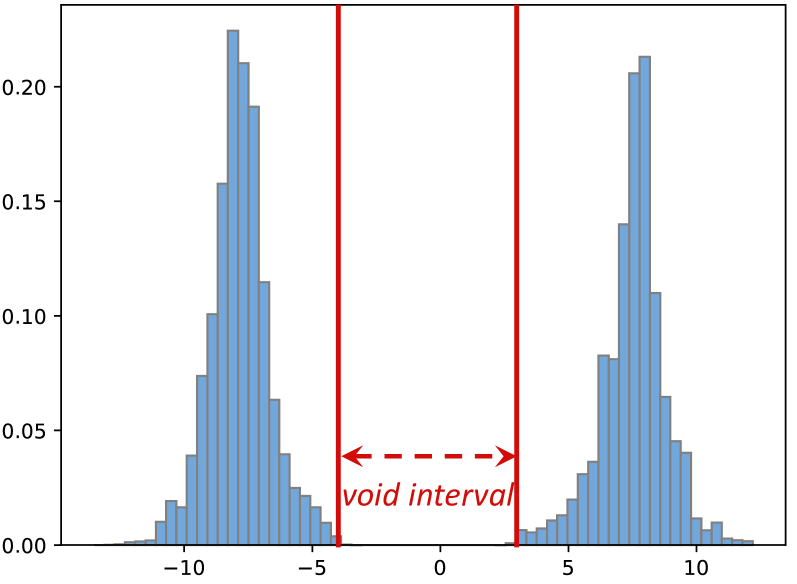
Directly quantizing SAM (Segment Anything Model) fails because of two unique activation issues: bimodal distributions in key-linear outputs and drastically different post-Softmax distributions across attention types.
Why it matters:
- SAM is computationally expensive, hindering deployment on edge devices; standard quantization causes severe accuracy drops due to these unique distribution shifts.
- Existing Vision Transformer quantization methods do not account for the specific bimodal outliers found in SAM's key projections.
- Diverse attention mechanisms in SAM (self-attention vs. two-way cross-attention) require specialized handling rather than a one-size-fits-all quantization approach.
Concrete Example:
In SAM's key-linear layer, activations cluster around two distinct peaks (e.g., -8 and +8) with a void in between. Standard quantization wastes bit-width representing the empty space, causing large errors. Additionally, image-to-token attention scores are mostly >0.01, while token-to-image scores are mostly near zero, yet prior methods quantize them identically.
Key Novelty
Bimodal Integration & Adaptive Granularity
- Bimodal Integration (BIG): Detects channels with bimodal peaks and flips the sign of negative-peak channels (and corresponding weights) to merge two peaks into one normal distribution.
- Adaptive Granularity Quantization (AGQ): Dynamically adjusts the base of the logarithmic quantizer for softmax outputs, allowing higher precision for small values or large values depending on the specific attention type (cross vs. self).
Architecture
The overall PTQ4SAM framework illustrating the Bimodal Integration (BIG) and Adaptive Granularity Quantization (AGQ) modules.
Evaluation Highlights
- Achieves lossless accuracy on instance segmentation using 6-bit quantization for SAM-L (Large) and SAM-H (Huge) variants compared to full precision.
- Reduces computational cost (FLOPs) by 3.9x and storage by 4.9x for the SAM-L model while maintaining performance within ~0.5% of the original.
- Outperforms state-of-the-art PTQ (Post-Training Quantization) methods like PD-Quant and Q-Drop by significant margins across varying bit-widths (e.g., 4-bit, 6-bit).
Breakthrough Assessment
8/10
First dedicated PTQ solution for SAM. The Bimodal Integration strategy is a clever, mathematically equivalent transformation that solves a specific structural issue in SAM, enabling low-bit inference where generic methods fail.