📝 Paper Summary
Model Compression
Efficient Deep Learning
Vision Transformers (ViT)
APHQ-ViT improves low-bit vision transformer quantization by replacing inaccurate Hessian approximations with a direct perturbation-based metric and substituting hard-to-quantize GELU activations with ReLU during reconstruction.
Core Problem
Vision Transformers suffer severe accuracy drops under ultra-low bit post-training quantization due to inaccurate output importance estimation and the difficult distribution of post-GELU activations.
Why it matters:
- Standard MSE loss treats all tokens equally, ignoring the critical class token and channel variations essential for ViT performance
- Existing Hessian-based metrics rely on Fisher Information Matrix approximations that fail when the model doesn't fit the data distribution well
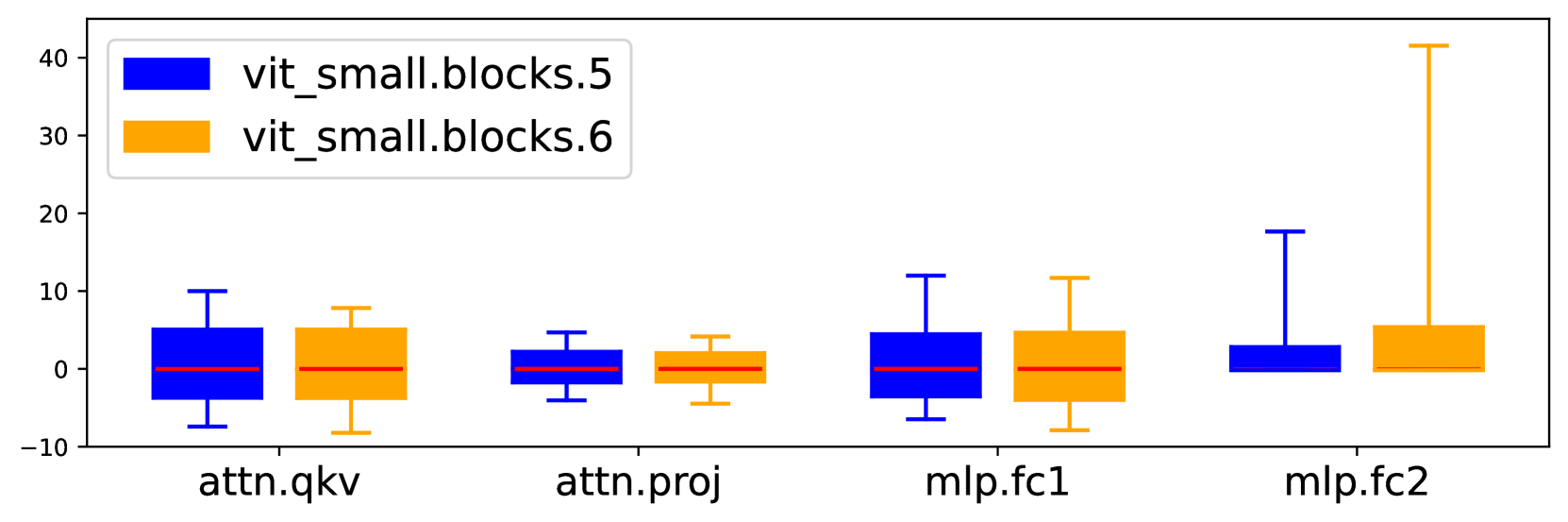
- Post-GELU activations have highly imbalanced distributions (dense negative values vs. sparse positive values) and large ranges, causing massive quantization errors
Concrete Example:
In post-GELU activations, negative values cluster densely in [-0.17, 0] while positive values are sparse and reach up to 40. Standard uniform quantizers waste bins on empty regions or clip important outliers, degrading accuracy significantly.
Key Novelty
Average Perturbation Hessian (APH) & MLP Reconstruction (MR)
- Calculates output sensitivity (Hessian) directly by perturbing outputs and measuring loss changes, removing errors from Fisher Information approximations used in prior work
- Replaces the quantization-unfriendly GELU activation with ReLU during an MLP reconstruction stage, utilizing knowledge distillation to align the ReLU network's behavior with the original GELU network
- Applies a clamping loss to restrict activation ranges, making the substituted ReLU activations much easier to quantize linearly
Architecture
The overall framework of APHQ-ViT, illustrating the block-wise quantization pipeline.
Evaluation Highlights
- Outperforms state-of-the-art PTQ4ViT by ~1-30% accuracy on ImageNet classification across various ViT architectures (ViT-S/B, DeiT-S/B, Swin-S/B) under 3-bit and 4-bit settings
- Achieves 78.43% top-1 accuracy on ViT-B with 4-bit quantization, surpassing the previous best method (PTQ4ViT) by 3.65%
- Demonstrates robust generalization to object detection (COCO) and instance segmentation tasks, where prior Hessian approximations often fail
Breakthrough Assessment
8/10
Significantly advances ultra-low bit (3-bit/4-bit) quantization for ViTs by fixing fundamental theoretical flaws in Hessian estimation and proposing a practical architectural substitution (ReLU for GELU) that simplifies the quantization landscape.