📝 Paper Summary
Latent Reasoning
Inference-time Refinement
Post-training Optimization
A training-free framework improves latent reasoning models by using contrastive feedback from model checkpoints and residual connections to guide and stabilize latent state evolution during inference.
Core Problem
Latent reasoning models (which process thoughts as embeddings rather than text) suffer from trajectory instability and lack explicit directional guidance, often drifting away from correct solutions during multi-step inference.
Why it matters:
- Explicit Chain-of-Thought (CoT) generates substantial token overhead, increasing computational costs
- Fixed reasoning trajectories in standard models prevent step-by-step refinement or error correction during generation
- Existing latent methods like Coconut lack mechanisms to recover from errors or ensure consistent progression toward the answer
Concrete Example:
In a multi-step math problem, a latent reasoning model might correctly encode the first step but, without guidance, the embedding at the second step drifts into an irrelevant semantic space. Unlike explicit CoT, the model cannot 'see' this error in text form to correct it, leading to a wrong final answer.
Key Novelty
Post-Training Latent Refinement Framework
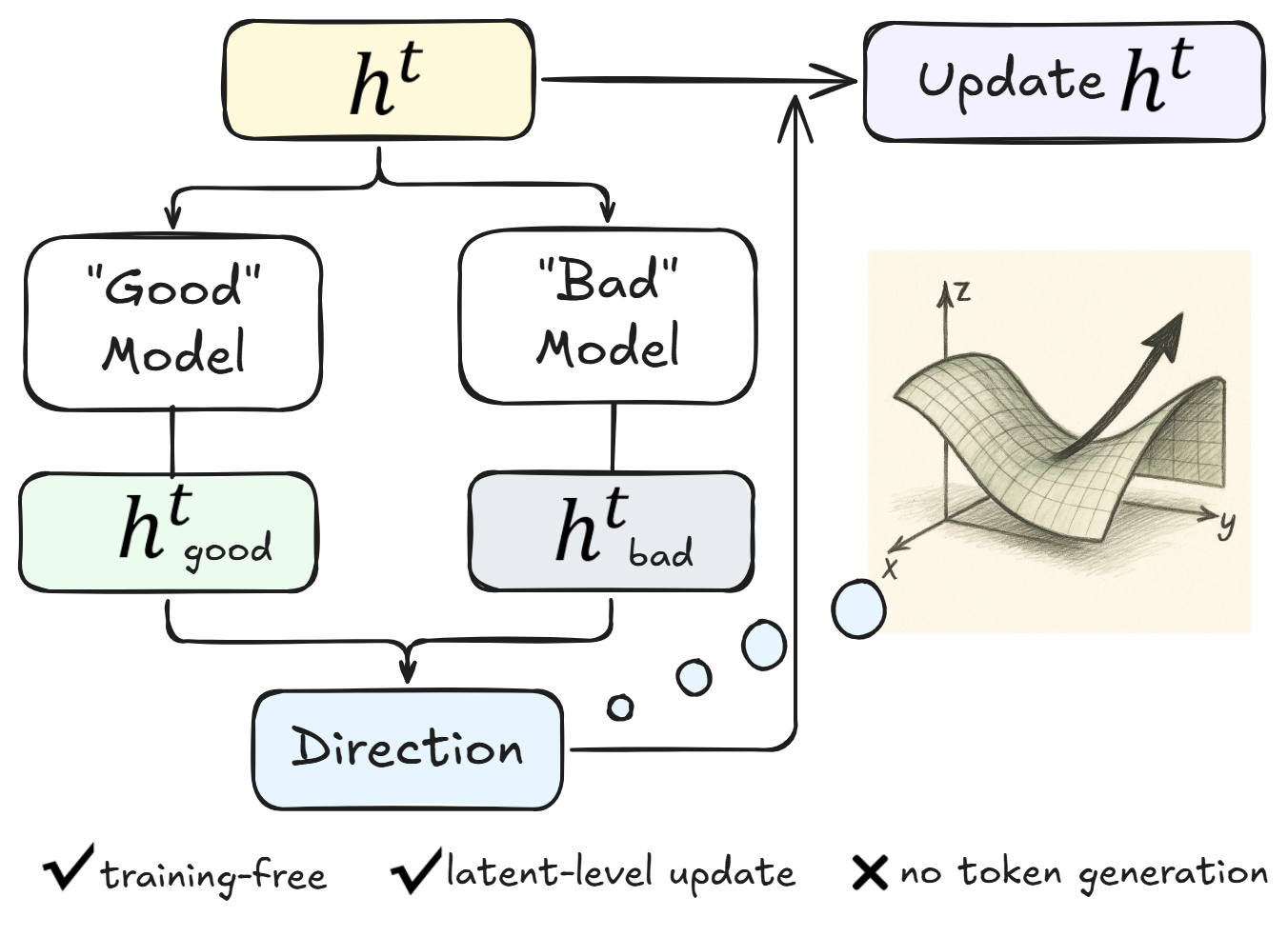
- Contrastive Reasoning Feedback: Uses gradients derived from the difference between intermediate 'strong' and 'weak' checkpoints (relative to each other) to nudge the latent state toward better reasoning directions on the fly.
- Residual Embedding Refinement: Implements a 'working memory' by blending the current latent state with the previous one via a residual connection, stabilizing the trajectory and preventing semantic drift.
Architecture
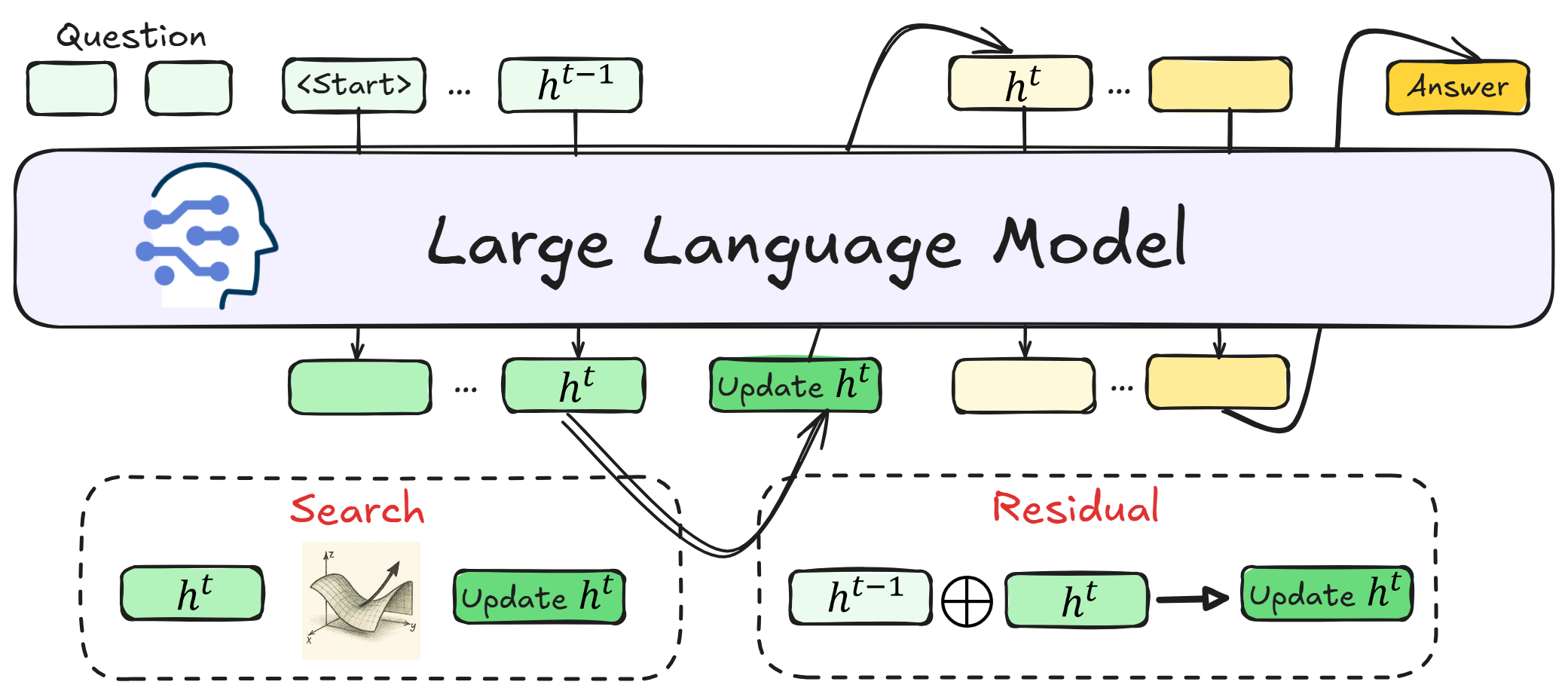
Overview of the Post-Training Latent Refinement Framework integration with Coconut.
Evaluation Highlights
- +5% accuracy gain on MathQA benchmark compared to the original Coconut latent reasoning method without additional training
- Demonstrates effectiveness across five distinct reasoning benchmarks (specific numbers for non-MathQA benchmarks not in text snippet)
Breakthrough Assessment
7/10
Offers a highly efficient, training-free solution to the stability problems of latent reasoning. While the scope is specific to latent models, the 'plug-and-play' nature is significant.