📊 Experiments & Results
Evaluation Setup
Language modeling perplexity and zero-shot task accuracy
Benchmarks:
- Llama-2-7B (Causal Language Modeling)
Metrics:
- Perplexity (PPL)
- Zero-shot accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Llama-2-7B | Block Error (MSE) | See Figure 2 | See Figure 2 | Significantly lower |
Experiment Figures
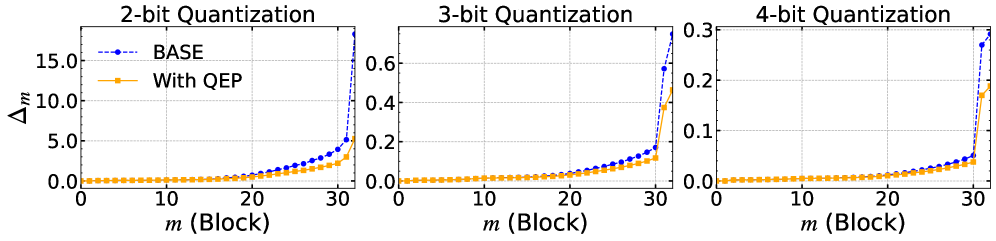
The accumulation of quantization error (MSE) across Transformer blocks in Llama-2-7B when quantizing the first 10 blocks.
Main Takeaways
- Quantization error accumulates exponentially across layers in standard PTQ methods.
- QEP significantly reduces this error accumulation by compensating for it in subsequent layers.
- The method is particularly effective in low-bit settings (e.g., 2-bit) where individual layer errors are large.
- The tunable alpha parameter is crucial for balancing error correction and overfitting, especially in MLP layers.