📝 Paper Summary
Model Compression
Diffusion Models
Vision Transformers
PTQ4DiT enables efficient low-bit inference of Diffusion Transformers by redistributing extreme values between weights and activations and calibrating quantization parameters based on temporal correlation across diffusion timesteps.
Core Problem
Diffusion Transformers (DiTs) are computationally expensive, and existing quantization methods fail because of 'salient channels' (extreme values) in activations/weights and significant temporal variations in activation distributions.
Why it matters:
- Generating a single 512x512 image with DiTs can take >20 seconds and 10^5 GFLOPs on high-end GPUs, making real-time deployment impractical
- Standard Post-training Quantization (PTQ) methods cause severe quality degradation in DiTs due to their unique architecture and multi-timestep inference nature
- Re-training DiTs for quantization (QAT) is often prohibitively expensive due to massive data and compute requirements
Concrete Example:
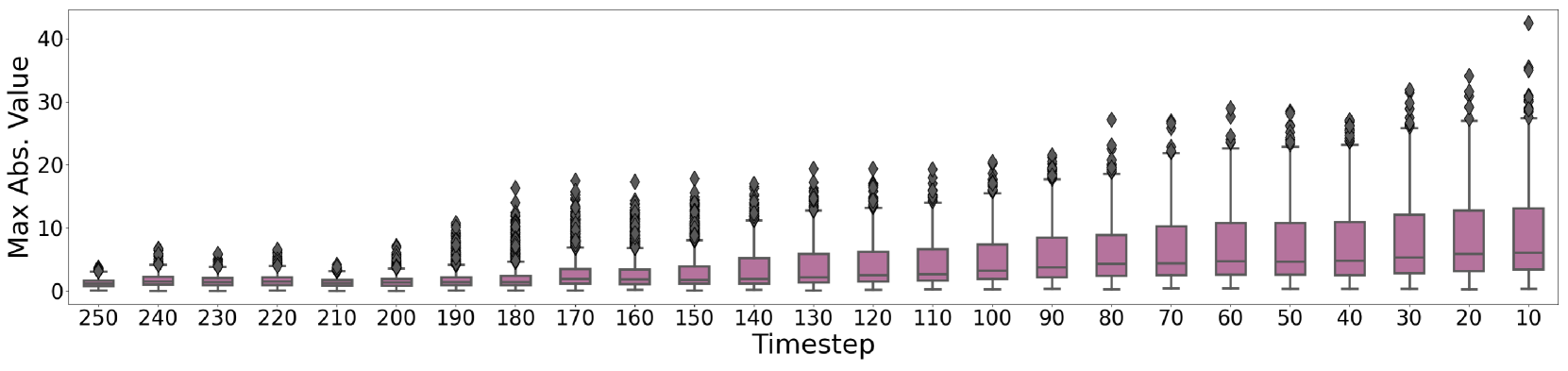
In DiT linear layers, certain channels have extreme magnitudes (salient channels). Standard quantization truncates these values or expands the range so much that precision for normal values is lost. Furthermore, the channels that are 'salient' change intensity across the 1000+ timesteps of diffusion, so a static quantization range effective at t=100 might destroy image quality at t=500.
Key Novelty
Channel-wise Salience Balancing (CSB) & Spearman’s ρ-guided Salience Calibration (SSC)
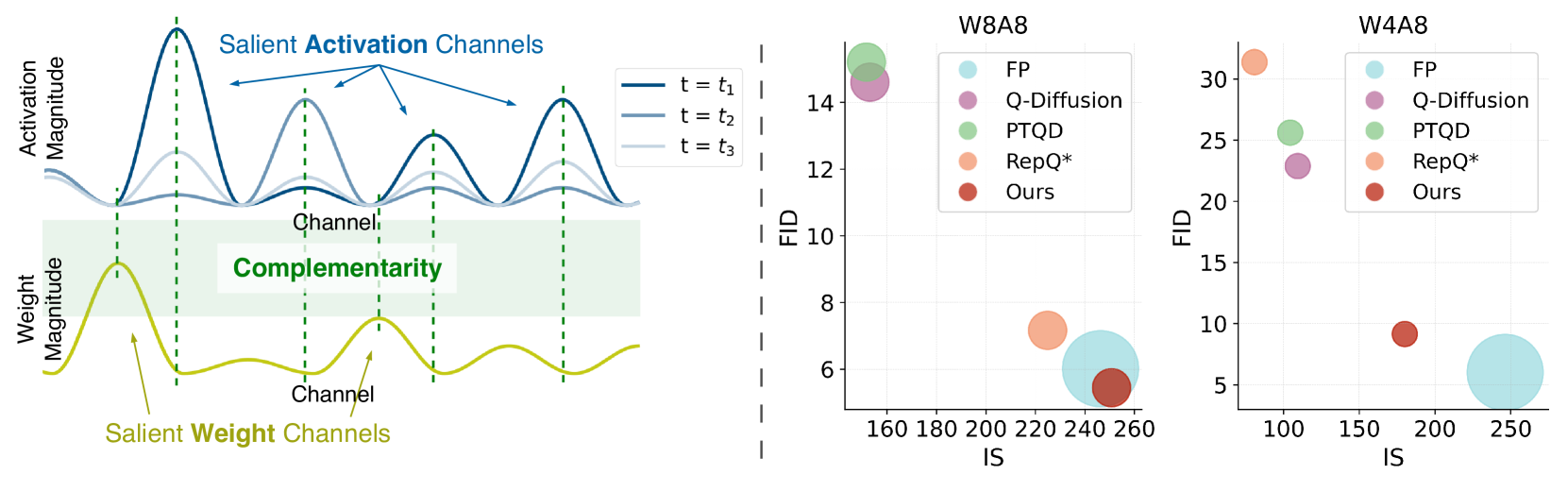
- CSB leverages the observation that extreme values (salience) rarely occur in the same channel for both weights and activations simultaneously. It mathematically migrates salience from activation to weight (or vice versa) to smooth out outliers before quantization.
- SSC accounts for the time-varying nature of diffusion by weighting the calibration process. It prioritizes timesteps where the correlation between activation and weight salience is low, ensuring the balancing parameters are robust across the full denoising trajectory.
Architecture
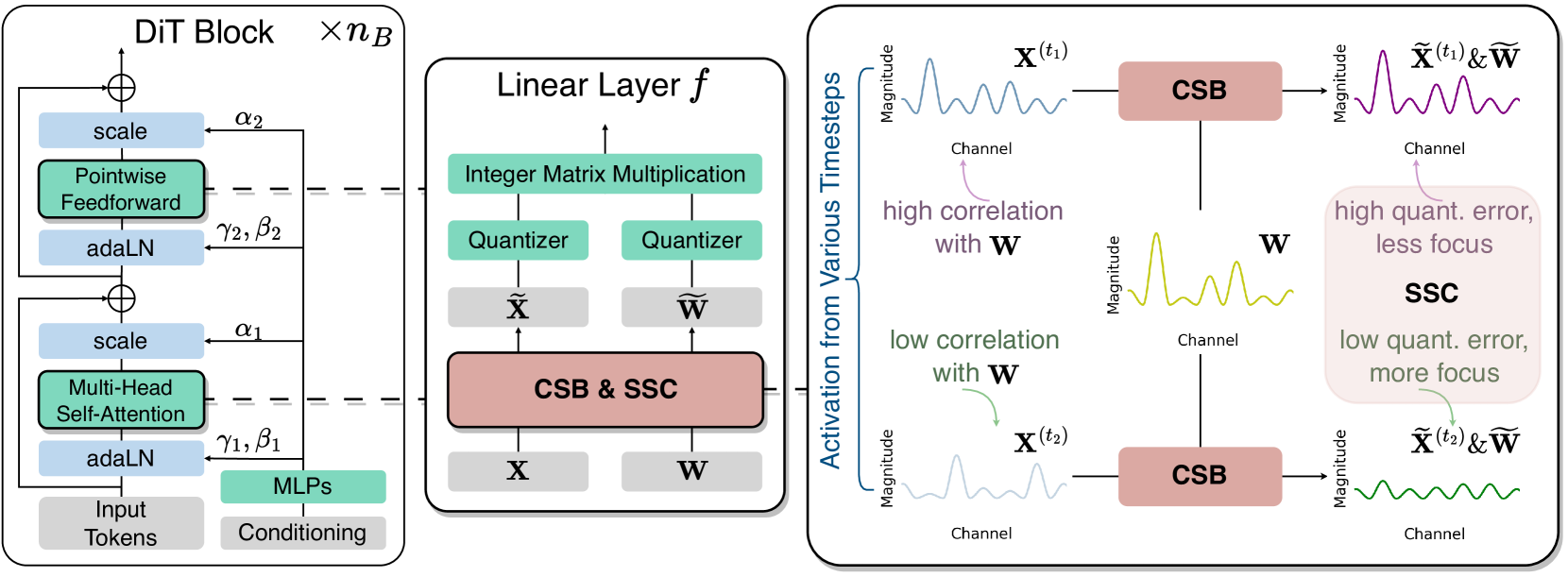
Overview of the PTQ4DiT framework. Left: Standard DiT block structure. Right: The proposed calibration and balancing mechanism.
Evaluation Highlights
- Achieves near-lossless generation quality at W8A8 (8-bit weights/activations) compared to full-precision DiT-XL/2 on ImageNet 256x256.
- Enables effective W4A8 (4-bit weights) quantization for the first time on DiTs, significantly outperforming baselines like SmoothQuant and QDiffuse.
- Reduces FID (Fréchet Inception Distance) gap significantly: At W4A8, PTQ4DiT achieves 9.86 FID on ImageNet 256x256, whereas the Min-Max baseline degrades to 58.74 FID.
Breakthrough Assessment
8/10
First successful PTQ method specifically tailored for Diffusion Transformers, addressing their unique temporal and distributional challenges. Enables W4A8 quantization where prior methods failed catastrophically.