📝 Paper Summary
Text-to-Video Generation
Model Post-Training / Alignment
T2V-Turbo-v2 improves video consistency distillation by integrating motion priors extracted from training data and decoupling data usage to circumvent reward model context limitations.
Core Problem
Existing T2V post-training methods rely on limited datasets and single reward models, failing to leverage high-quality videos or motion priors due to computational costs and reward model context limits.
Why it matters:
- Proprietary models (Gen-3, Sora) vastly outperform open-source models, creating a significant accessibility gap in video generation research
- Current reward models have short context lengths (e.g., 77 tokens), making them ineffective for optimizing alignment on high-quality datasets with dense, detailed captions
- Calculating advanced guidance (like motion priors) during training is prohibitively expensive (memory and time) for standard consistency distillation loops
Concrete Example:
When training on high-quality datasets like VidGen-1M with dense captions, the reward model (e.g., CLIP) truncates the text, leading to poor supervision. Additionally, calculating motion guidance requires expensive DDIM inversion at every step, which typically consumes >40GB GPU memory, making it infeasible for training.
Key Novelty
Offline Motion-Guided Consistency Distillation
- Treats the training video itself as the 'ideal reference' for motion, extracting temporal attention maps to guide the student model toward realistic dynamics during distillation
- Decouples training data: uses high-quality/dense-caption data for the consistency loss (visual quality) but short-caption data for the reward loss (alignment) to avoid context truncation artifacts
- Pre-calculates the computationally expensive guided ODE trajectories before training, enabling the use of complex energy functions (motion guidance) without runtime memory overhead
Architecture
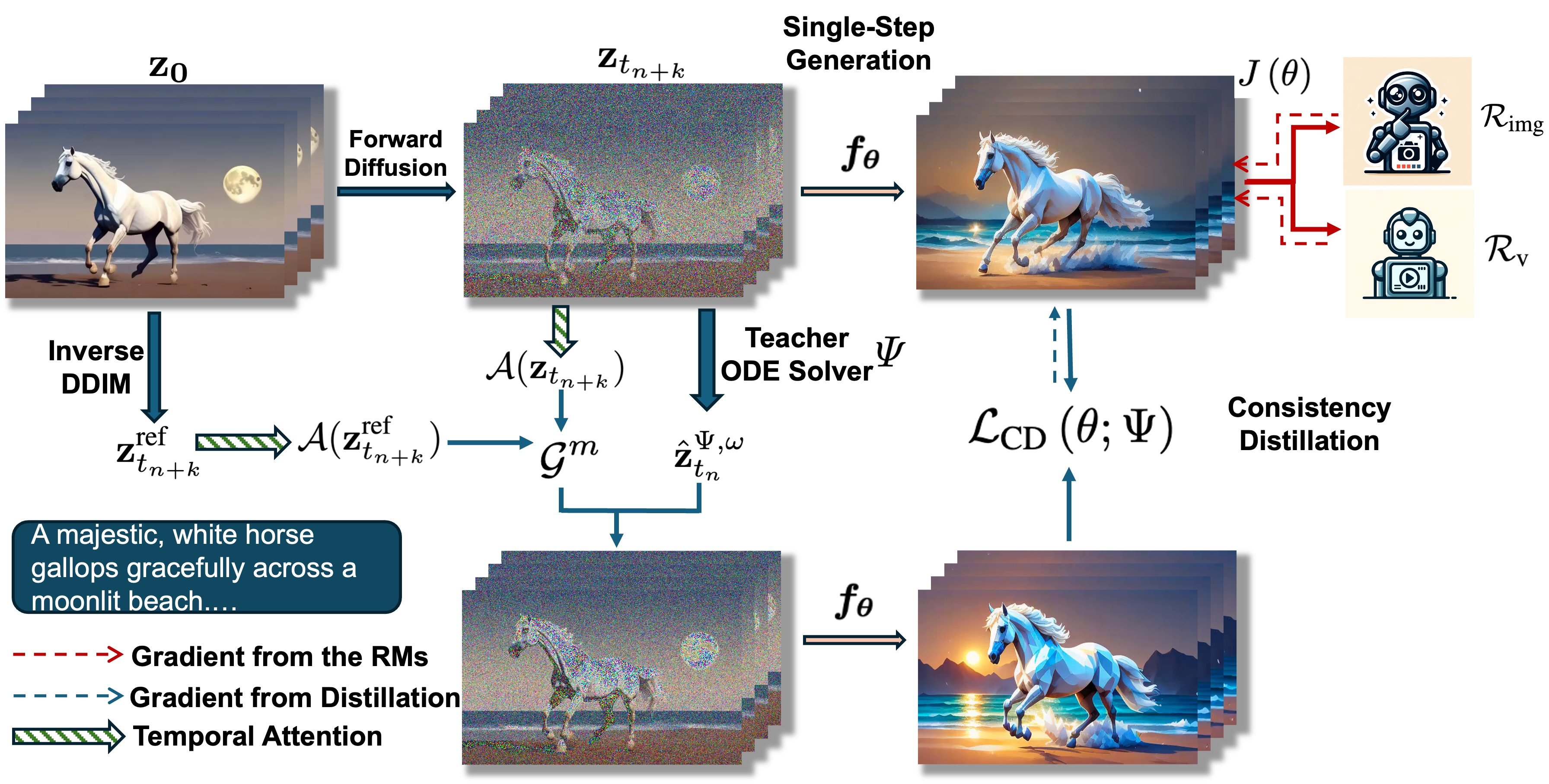
The training pipeline of T2V-Turbo-v2, illustrating the two-stage process: Data Preprocessing and Consistency Distillation.
Evaluation Highlights
- Achieves VBench Total Score of 85.13, establishing a new SOTA and surpassing proprietary systems like Gen-3 and Kling
- Improves Total Score by +5.19 points (76.15 → 81.34) over the VideoLCM baseline on WebVid-10M data by integrating reward feedback
- Demonstrates that combining diverse reward models (HPSv2.1 + CLIP + InternVideo2) yields superior text-video alignment compared to using HPSv2.1 alone
Breakthrough Assessment
9/10
Sets a new open-source SOTA beating top proprietary models. Introduces a clever, resource-efficient way to incorporate expensive test-time guidance into training via offline pre-calculation.
