📝 Paper Summary
Reinforcement Learning for LLMs
System Scalability
Distributed Training Frameworks
Laminar scales RL post-training by decoupling actor and rollout execution via a relay tier and dynamic trajectory repacking, enabling efficient asynchronous updates without global synchronization.
Core Problem
Existing RL frameworks rely on global weight synchronization that stalls all rollouts until the slowest trajectory finishes, causing severe GPU underutilization due to skewed generation latencies.
Why it matters:
- Reasoning and agentic tasks exhibit extreme long-tail skewness (99th percentile length 10x median), making synchronous lockstep inefficient
- Current asynchronous methods use rigid staleness bounds that either hurt convergence (high staleness) or fail to hide latency (low staleness)
- Scaling to thousands of GPUs is bottlenecked by the inability to manage diverse trajectory completion times efficiently
Concrete Example:
In math reasoning tasks, generating a complex solution might take 10x longer than a simple one. In synchronous systems, 1023 GPUs sit idle waiting for 1 GPU to finish the long solution before any can update weights. Laminar allows the 1023 fast GPUs to update and continue immediately.
Key Novelty
Trajectory-Level Asynchrony with Relay Workers
- Decouples the actor from rollouts using intermediate 'relay workers' that serve as a distributed parameter store, allowing rollouts to fetch new weights anytime without interrupting the actor
- Implements 'dynamic repacking' to detect rollouts stuck on long-tail generations and move their pending work to a few dedicated nodes, freeing the rest to update and process new batches
- Enables each trajectory to be generated and consumed independently, removing the global lockstep requirement of prior asynchronous methods
Architecture
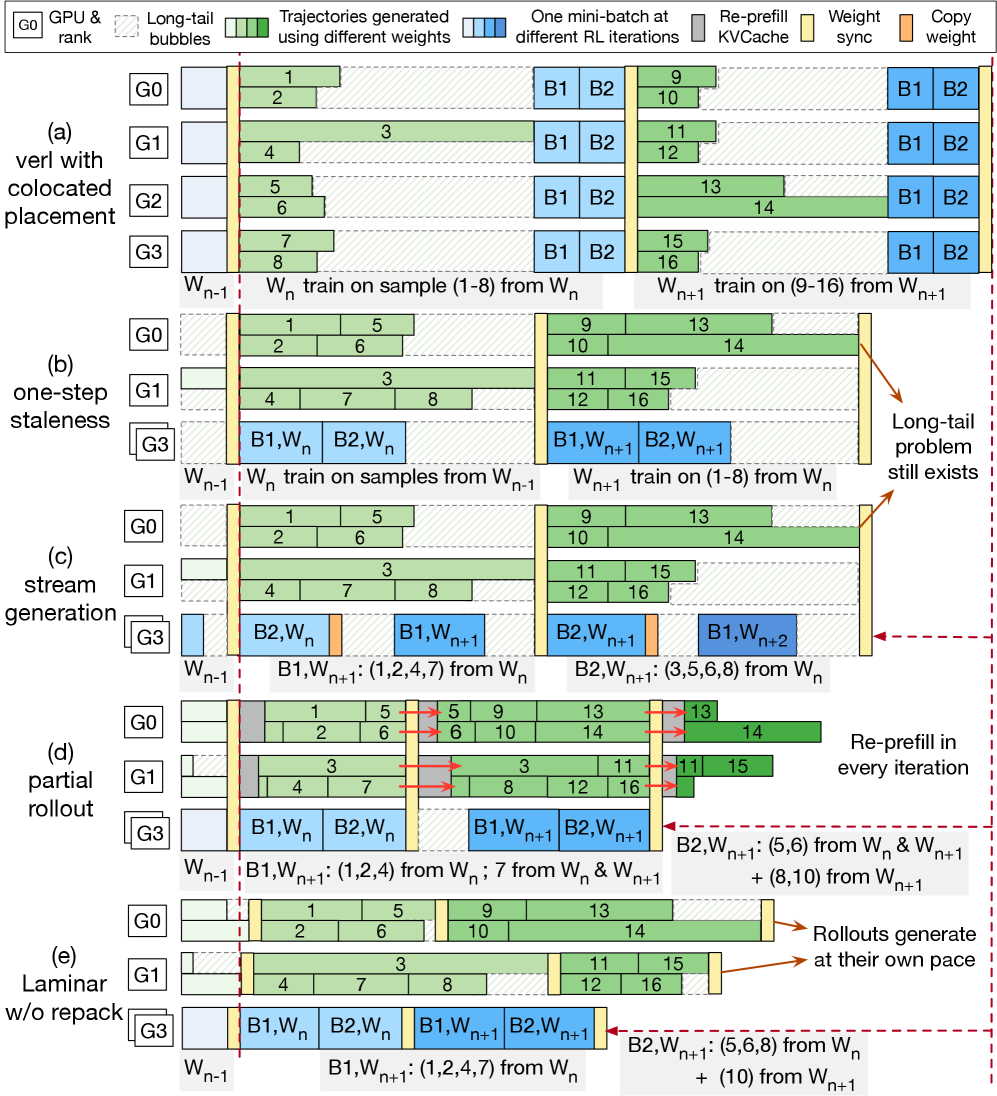
Comparison of RL pipelines. Laminar (3e) shows fully decoupled Actor and Rollouts with a Relay tier, contrasting with Synchronous (3a) and rigid Asynchronous (3b/c/d) designs.
Evaluation Highlights
- Achieves up to 5.48x training throughput speedup over state-of-the-art systems (Real-time PPO) on a 1024-GPU cluster
- Maintains or improves model convergence compared to synchronous baselines, whereas high-staleness asynchronous baselines degrade performance
- Reduces the impact of long-tail generation latency, with generation stage throughput scaling nearly linearly compared to baselines that plateau
Breakthrough Assessment
9/10
Addresses the critical bottleneck of long-tail generation in RLHF at production scale. The architectural decoupling and dynamic repacking offer a practical, high-impact solution for training reasoning models.