📝 Paper Summary
LLM Representation Learning
Mechanistic Interpretability
Training Dynamics
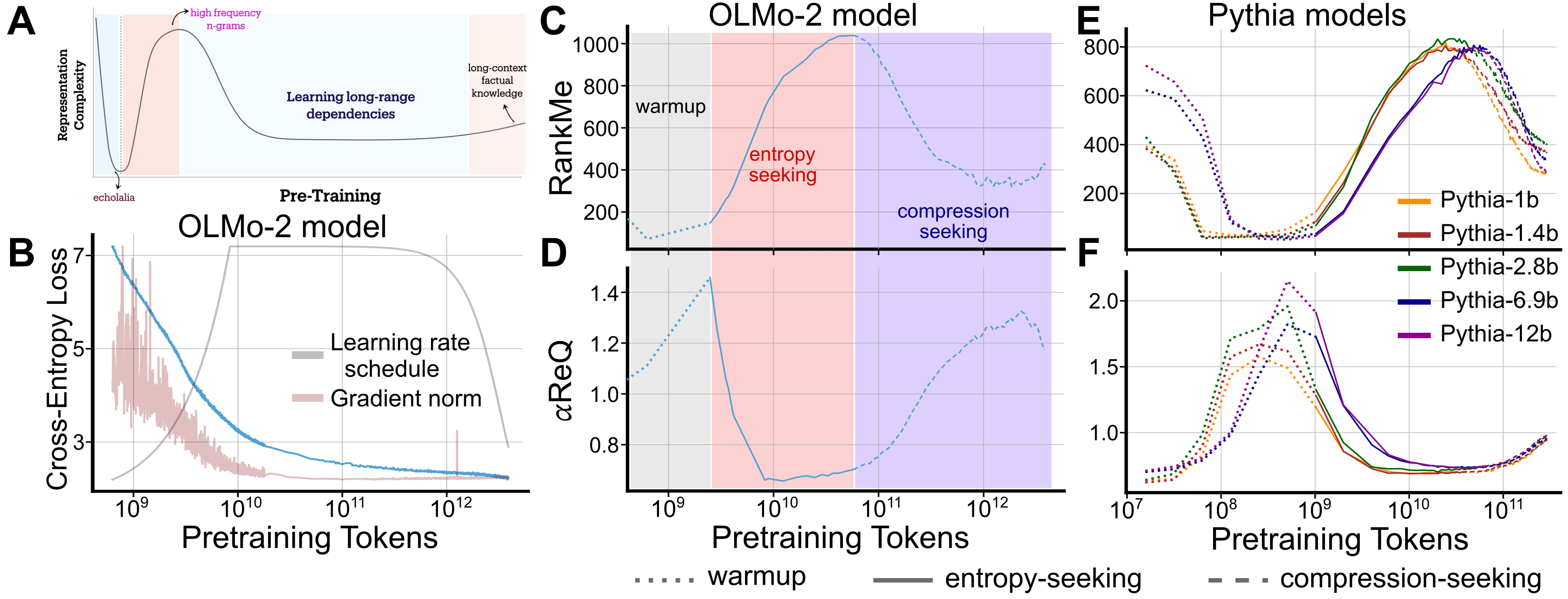
LLM representations evolve through three distinct geometric phases during pretraining—warmup collapse, entropy-seeking expansion, and compression-seeking consolidation—which correlate with specific capabilities like memorization and generalization.
Core Problem
Standard training metrics like loss decrease monotonically and fail to explain the qualitative shifts in capabilities and internal structure that occur during LLM training.
Why it matters:
- Practitioners rely on loss curves that mask internal structural changes, making it hard to diagnose when specific capabilities (like reasoning vs. memorization) emerge
- Understanding how high-dimensional representations evolve is crucial for optimizing training recipes to target specific behaviors (e.g., robustness vs. diversity)
- Current post-training methods (RLVR, DPO) alter model behavior, but their impact on the underlying representational geometry remains largely unmapped
Concrete Example:
During the 'warmup' phase, models may exhibit 'echolalia' (repetitive outputs) despite decreasing loss, because representations have collapsed onto a few dominant directions. Later, RLVR improves math scores but reduces generative diversity, a trade-off invisible to simple loss metrics but visible in geometric compression.
Key Novelty
Spectral Geometric Phase Analysis
- Identifies a consistent three-phase evolution in representation geometry using spectral metrics (RankMe, alpha-ReQ): 'warmup' (collapse), 'entropy-seeking' (expansion/memorization), and 'compression-seeking' (consolidation/generalization)
- Links these geometric phases to specific downstream capabilities: expansion correlates with n-gram memorization, while compression correlates with long-range dependency learning and reasoning
- Demonstrates that post-training methods drive opposing geometric shifts: SFT and DPO expand the manifold ('entropy-seeking'), while RLVR contracts it ('compression-seeking')
Architecture
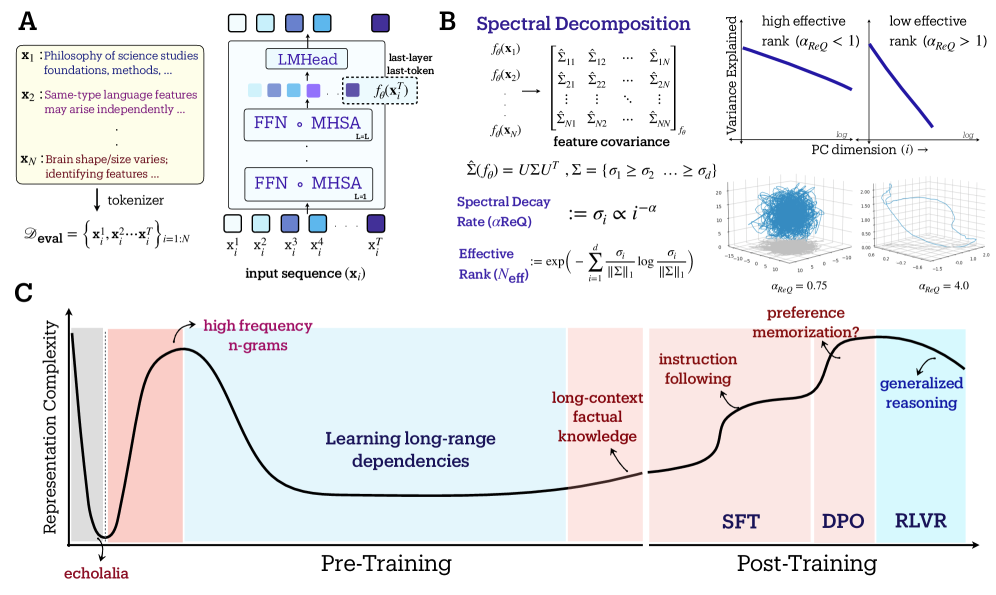
Conceptual diagram of the three geometric phases during pretraining: Warmup (Collapse), Entropy-Seeking (Expansion), and Compression-Seeking (Consolidation).
Evaluation Highlights
- Discovered a universal 3-phase geometric evolution across OLMo (1B-7B) and Pythia (160M-12B) model families during pretraining
- SFT on Anthropic-HH caused a monotonic increase in effective rank (RankMe), correlating with a drop in win-rate from 14% to 9% against Alpaca Farm reference due to overfitting
- RLVR training improved pass@16 accuracy but degraded pass@256 accuracy compared to the base model, directly tracking with a geometric contraction (compression-seeking)
Breakthrough Assessment
8/10
Provides a fundamental, mechanistic characterization of LLM learning dynamics that goes beyond loss curves. The identification of distinct geometric phases linking to specific capabilities is a significant theoretical advance.