📝 Paper Summary
Language Model Pre-training Theory
Post-training dynamics
Test-time scaling
The paper proves next-token prediction implicitly optimizes 'coverage'—the probability of generating high-quality responses—more effectively than cross-entropy suggests, explaining why pre-training enables downstream Best-of-N scaling.
Core Problem
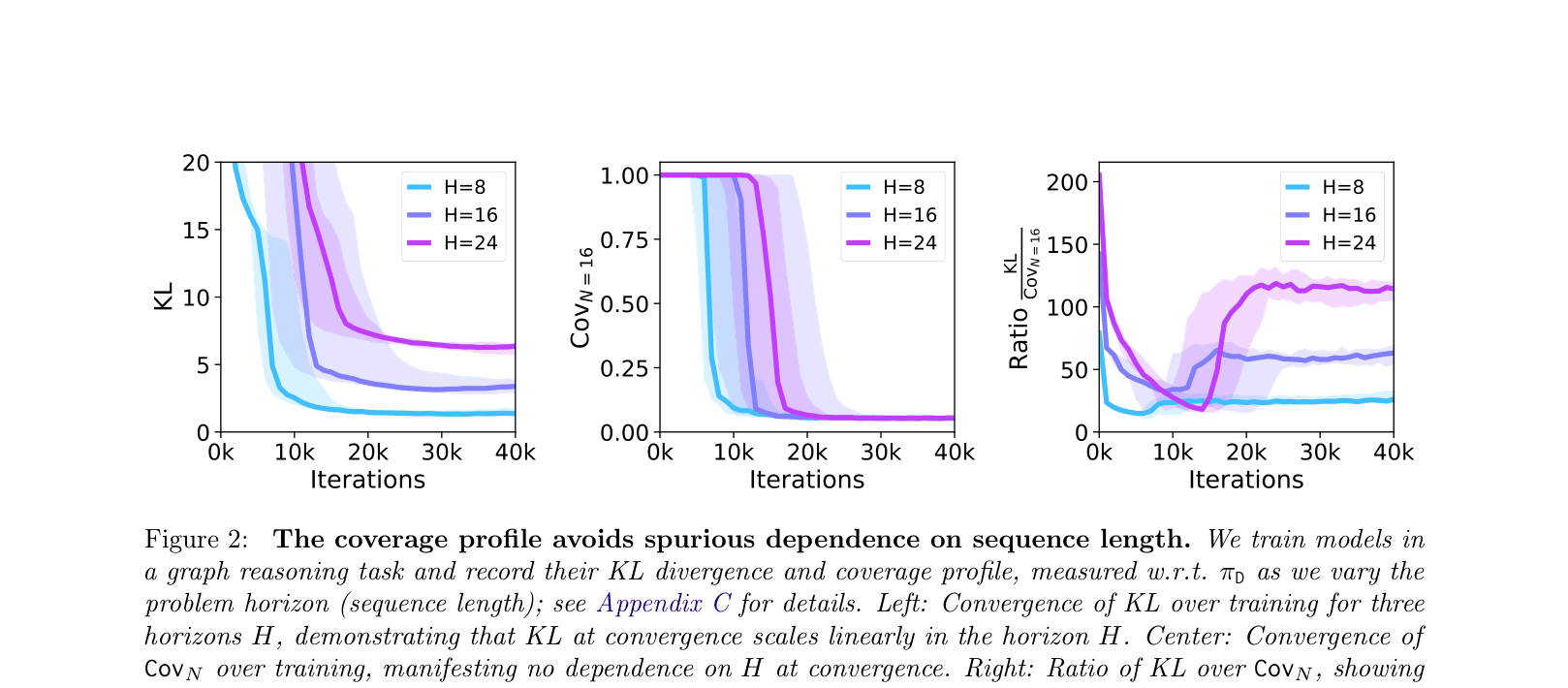
Cross-entropy loss is a poor predictor of downstream performance (specifically Best-of-N sampling); theoretical bounds based on cross-entropy scale linearly with sequence length, predicting vacuous performance for long sequences.
Why it matters:
- Explains the disconnect where models with lower pre-training loss do not always yield better downstream results (the 'Goodhart's Law' of pre-training)
- Standard scaling laws based on cross-entropy fail to capture the mechanisms that actually enable successful post-training and test-time scaling
- Identifies that Stochastic Gradient Descent (SGD) can fail to optimize coverage effectively compared to Maximum Likelihood Estimation (MLE) due to sequence length dependence
Concrete Example:
In a graph reasoning task (Figure 1), a model selected by minimizing KL divergence achieves lower Pass@8 performance (~0.96) compared to a model selected by a tournament procedure (~1.00), showing that cross-entropy/KL misidentifies the best model.
Key Novelty
The Coverage Principle
- Defines 'Coverage Profile' as the probability mass the model assigns to high-quality responses, showing it is necessary and sufficient for Best-of-N success
- Proves that next-token prediction (MLE) implicitly optimizes coverage at a faster rate than cross-entropy, specifically avoiding spurious dependence on sequence length
- Demonstrates that the logarithmic loss has a 'one-sided' property that forces models to cover the data distribution even when cross-entropy is large
Architecture
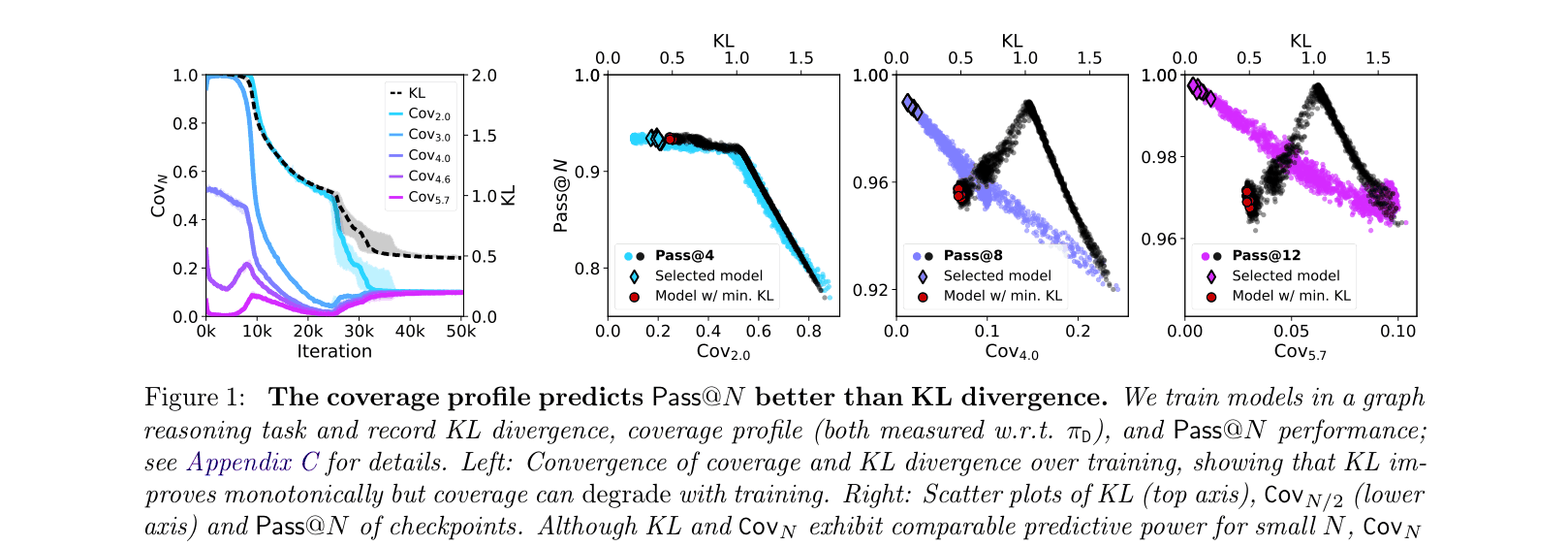
Comparison of KL Divergence vs Coverage Profile as predictors of Pass@N (Best-of-N) performance.
Evaluation Highlights
- Proves next-token prediction coverage generalizes at rate proportional to 1/log(N), faster than standard bounds
- Gradient normalization provably removes linear dependence on sequence length H from SGD convergence rates
- Tournament-based checkpoint selection consistently identifies models with higher Pass@N than selection based on minimal KL divergence
Breakthrough Assessment
8/10
Provides a fundamental theoretical link between pre-training and post-training that explains empirical observations (like the inadequacy of cross-entropy). Proposes actionable algorithmic interventions (gradient norm, tournament selection).